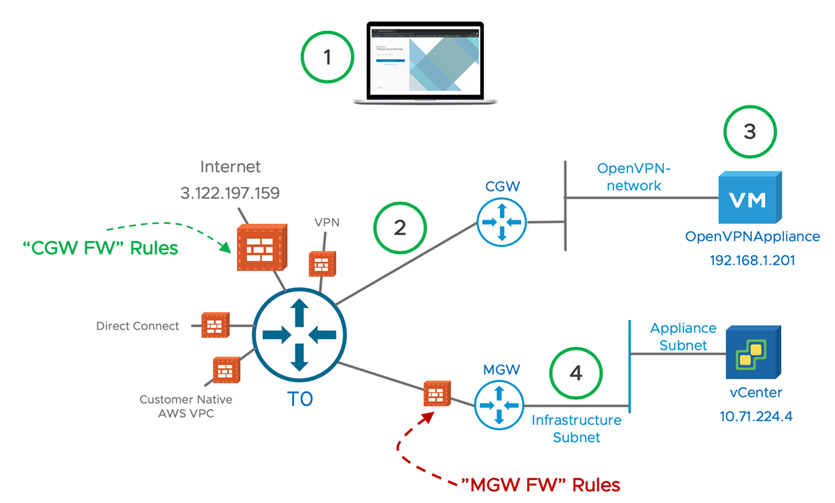
Learning the k8s ropes…
This is not a how to article to get vSphere with Tanzu up and running, there are plenty of guides out there, here and here. This post is more of a “lets have some fun with Kubernetes now that I have a vSphere with Tanzu cluster to play with“.
Answering the following question would be a good start to get to grips with understanding Kubernetes from a VMware perspective.
How do I do things that I did in the past in a VM but now do it with Kubernetes in a container context instead?
For example building the certbot application in a container instead of a VM.
Lets try to create an Ubuntu deployment that deploys one Ubuntu container into a vSphere Pod with persistent storage and a load balancer service from NSX-T to get to the /bin/bash shell of the deployed container.
Let’s go!
I created two yaml files for this, accessible from Github. You can read up on what these objects are here.
| Filename | Whats it for? | What does it do? | Github link |
|---|---|---|---|
| certbot-deployment.yaml | k8s deployment specification | Deploys one ubuntu pod, claims a 16Gb volume and mounts it to /dev/sdb and creates a load balancer to enable remote management with ssh. | ubuntu-deployment.yaml |
| certbot-pvc.yaml | persistent volume claim specification | Creates a persistent volume of 16Gb size from the underlying vSphere storage class named tanzu-demo-storage. The PVC is then consumed by the deployment. | ubuntu-pvc.yaml |
Here’s the certbot-deployment.yaml file that shows the required fields and object spec for a Kubernetes Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: certbot
spec:
replicas: 1
selector:
matchLabels:
app: certbot
template:
metadata:
labels:
app: certbot
spec:
volumes:
- name: certbot-storage
persistentVolumeClaim:
claimName: ubuntu-pvc
containers:
- name: ubuntu
image: ubuntu:latest
command: ["/bin/sleep", "3650d"]
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: "/mnt/sdb"
name: certbot-storage
restartPolicy: Always
---
apiVersion: v1
kind: Service
metadata:
labels:
app: certbot
name: certbot
spec:
ports:
- port: 22
protocol: TCP
targetPort: 22
selector:
app: certbot
sessionAffinity: None
type: LoadBalancerHere’s the certbot-pvc.yaml file that shows the required fields and object spec for a Kubernetes Persistent Volume Claim.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: certbot-pvc
labels:
storage-tier: tanzu-demo-storage
availability-zone: home
spec:
accessModes:
- ReadWriteOnce
storageClassName: tanzu-demo-storage
resources:
requests:
storage: 16GiFirst deploy the PVC claim with this command:
kubectl apply -f certbot-pvc.yaml
Then deploy the deployment with this command:
kubectl.exe apply -f certbot-deployment.yaml
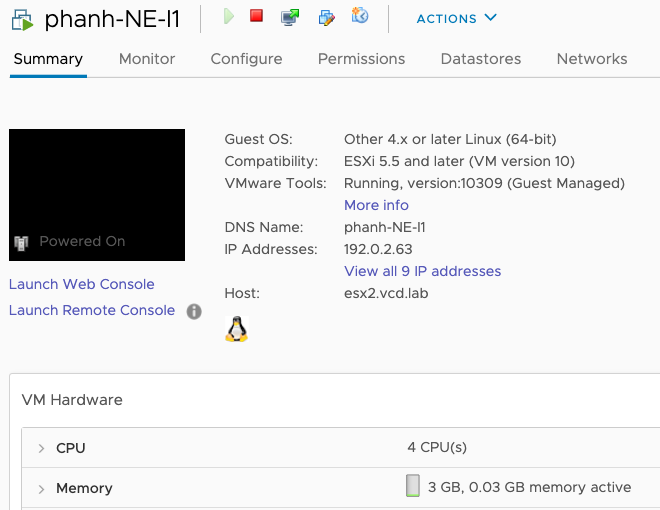
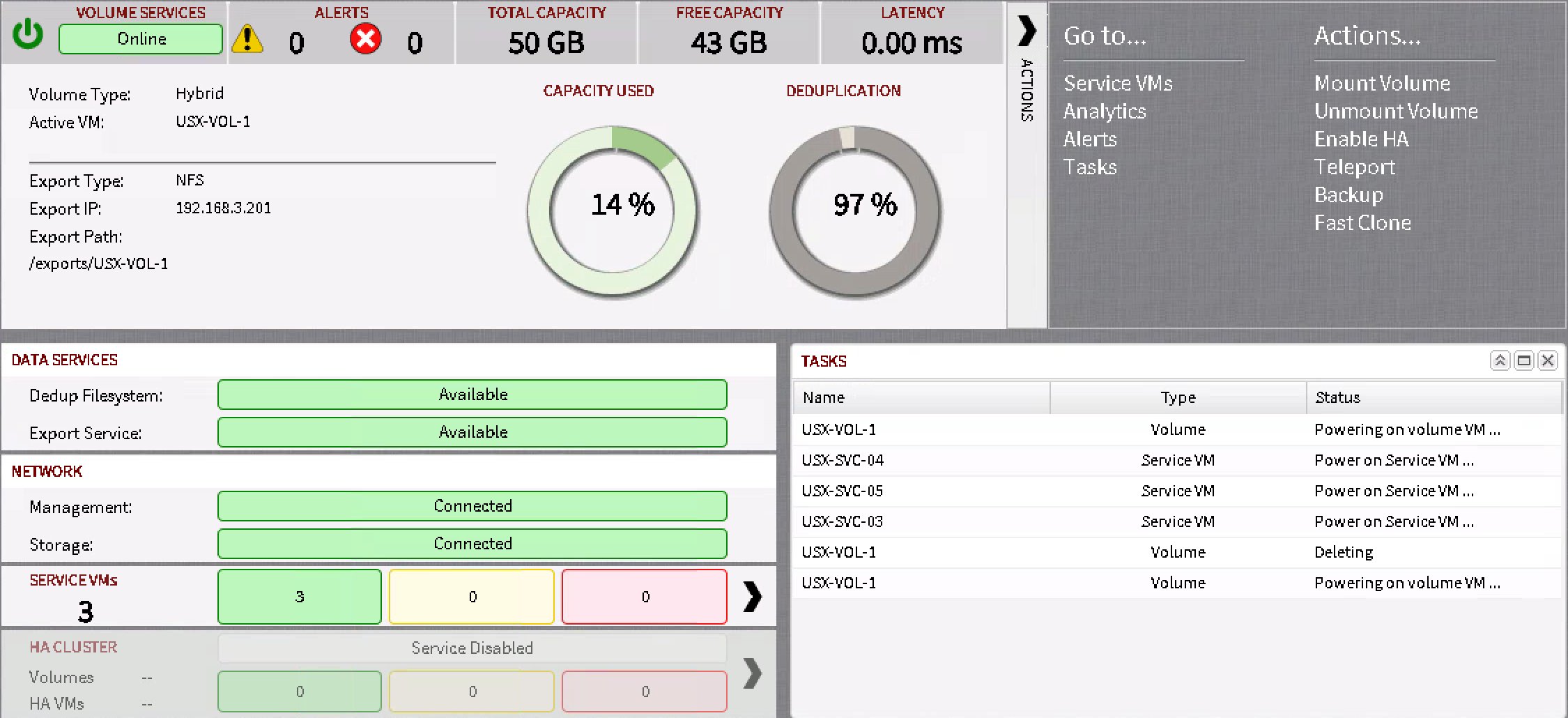
Magic happens and you can monitor the vSphere client and kubectl for status. Here are a couple of screenshots to show you whats happening.


kubectl describe deployment certbot
Name: certbot
Namespace: new
CreationTimestamp: Thu, 11 Mar 2021 23:40:25 +0200
Labels: <none>
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=certbot
Replicas: 1 desired | 1 updated | 1 total | 1 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=certbot
Containers:
ubuntu:
Image: ubuntu:latest
Port: <none>
Host Port: <none>
Command:
/bin/sleep
3650d
Environment: <none>
Mounts:
/mnt/sdb from certbot-storage (rw)
Volumes:
certbot-storage:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: certbot-pvc
ReadOnly: false
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: certbot-68b4747476 (1/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 44m deployment-controller Scaled up replica set certbot-68b4747476 to 1kubectl describe pvc
Name: certbot-pvc
Namespace: new
StorageClass: tanzu-demo-storage
Status: Bound
Volume: pvc-418a0d4a-f4a6-4aef-a82d-1809dacc9892
Labels: availability-zone=home
storage-tier=tanzu-demo-storage
Annotations: pv.kubernetes.io/bind-completed: yes
pv.kubernetes.io/bound-by-controller: yes
volume.beta.kubernetes.io/storage-provisioner: csi.vsphere.vmware.com
volumehealth.storage.kubernetes.io/health: accessible
Finalizers: [kubernetes.io/pvc-protection]
Capacity: 16Gi
Access Modes: RWO
VolumeMode: Filesystem
Mounted By: certbot-68b4747476-pq5j2
Events: <none>kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
certbot 1/1 1 1 47m
kubectl get pods
NAME READY STATUS RESTARTS AGE
certbot-68b4747476-pq5j2 1/1 Running 0 47m
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
certbot-pvc Bound pvc-418a0d4a-f4a6-4aef-a82d-1809dacc9892 16Gi RWO tanzu-demo-storage 84mLet’s log into our pod, note the name from the kubectl get pods command above.
certbot-68b4747476-pq5j2
Its not yet possible to log into the pod using SSH since this is a fresh container that does not have SSH installed, lets log in first using kubectl and install SSH.
kubectl exec --stdin --tty certbot-68b4747476-pq5j2 -- /bin/bashYou will then be inside the container at the /bin/bash prompt.
root@certbot-68b4747476-pq5j2:/# ls
bin dev home lib32 libx32 mnt proc run srv tmp var
boot etc lib lib64 media opt root sbin sys usr
root@certbot-68b4747476-pq5j2:/#Lets install some tools and configure ssh.
apt-get update
apt-get install iputils-ping
apt-get install ssh
passwd root
service ssh restart
exitBefore we can log into the container over an SSH connection, we need to find out what the external IP is for the SSH service that the NSX-T load balancer configured for the deployment. You can find this using the command:
kubectl get services
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
certbot LoadBalancer 10.96.0.44 172.16.2.3 22:31731/TCP 51mThe IP that we use to get to the Ubuntu container over SSH is 172.16.2.3. Lets try that with a putty/terminal session…
login as: root
certbot@172.16.2.3's password:
Welcome to Ubuntu 20.04.2 LTS (GNU/Linux 4.19.126-1.ph3-esx x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
This system has been minimized by removing packages and content that are
not required on a system that users do not log into.
To restore this content, you can run the 'unminimize' command.
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
$ ls
bin dev home lib32 libx32 mnt proc run srv tmp var
boot etc lib lib64 media opt root sbin sys usr
$ df
Filesystem 1K-blocks Used Available Use% Mounted on
overlay 258724 185032 73692 72% /
/mnt/sdb 16382844 45084 16321376 1% /mnt/sdb
tmpfs 249688 12 249676 1% /run/secrets/kubernetes.io/servic eaccount
/dev/sda 258724 185032 73692 72% /dev/termination-log
$
You can see that there is a 16Gb mount point at /mnt/sdb just as we specified in the specifications and remote SSH access is working.