Atlantis HyperScale appliances come with effective capacities of 12TB, 24TB and 48TB depending on the model that is deployed. These capacities are what we refer to as effective capacity, i.e., the available capacity after in-line de-duplication that occurs when data is stored onto HyperScale Volumes. HyperScale Volumes always de-duplicate data first before writing data down to the local flash drives. This is what is known as in-line deduplication which is very different from post-de-duplication which will de-duplicate data after it is written down to disk. The latter incurs storage capacity overhead as you will need the capacity to store the data before the post-process de-duplication is able to then de-duplicate. This is why HyperScale appliances only require three SSDs per node to provide the 12TB of effective capacity at 70% de-duplication.
Breaking it down
| HyperScale SuperMicro | CX-12 |
| Number of nodes | 4 |
| Number of SSDs per node | 3 |
| SSD capacity | 400GB |
| Usable flash capacity per node | 1,200GB |
| Cluster RAW flash capacity | 4,800GB |
| Cluster failure tolerance | 1 |
| Usable flash capacity per cluster | 3,600GB |
| Effective capacity with 70% dedupe | 12,000GB |
Data Reduction Table
| De-Dupe Rate (%) |
Reduction Rate (X) |
| 95 |
20.00 |
| 90 |
10.00 |
| 80 |
5.00 |
| 75 |
4.00 |
| 70 |
3.33 |
| 65 |
2.86 |
| 60 |
2.50 |
| 55 |
2.22 |
| 50 |
2.00 |
| 45 |
1.82 |
| 40 |
1.67 |
| 35 |
1.54 |
| 30 |
1.43 |
| 25 |
1.33 |
| 20 |
1.25 |
| 15 |
1.18 |
| 10 |
1.11 |
| 5 |
1.05 |
Formulas
Formula for calculating Reduction Rate

Taking the capacity from a typical HyperScale appliance of 3,600GB, this will give 12,000TB of effective capacity.
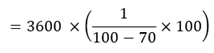
Summary
HyperScale provides a guarantee of 12TB per CX-12 appliance, however some workloads such as DEV/TEST private clouds and stateless VDI workloads could see as much as 90% data reduction. That’s 36,000GB of effective capacity. Do the numbers yourself, in-line de-duplication eliminates the need for lots of local flash drives or slower high capacity SAS or SATA drives. HyperScale runs the same codebase as USX and as such utilizes RAM to perform the in-line de-duplication which eliminates the need for add-in hardware cards or SSDs as staging capacity for de-duplication.
For more information please visit this site www.atlantiscomputing.com/hyperscale.

Nice article, but i think that should be 12,000GB and not 12,000TB. 🙂