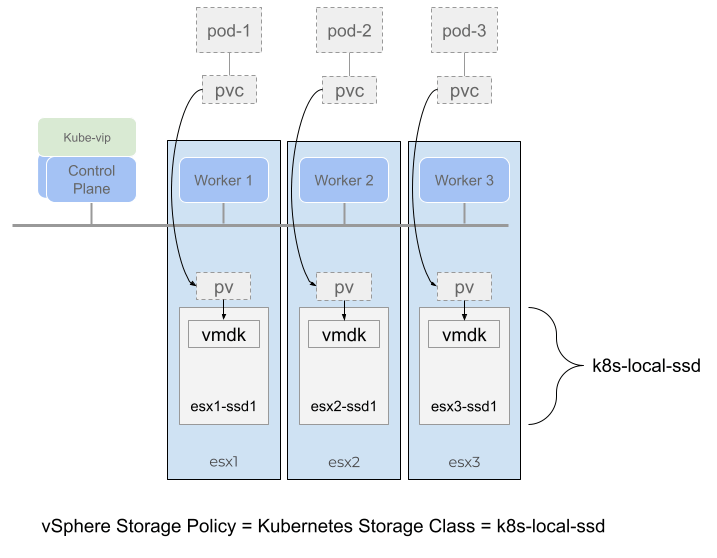
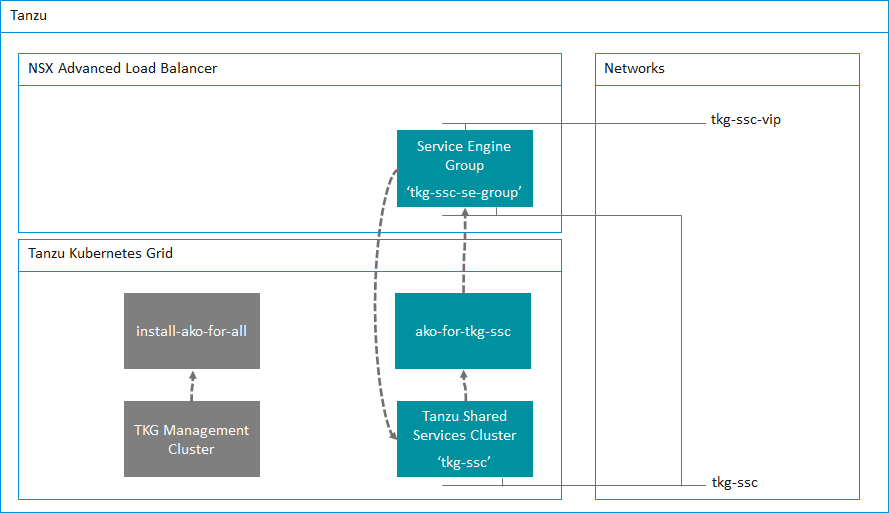
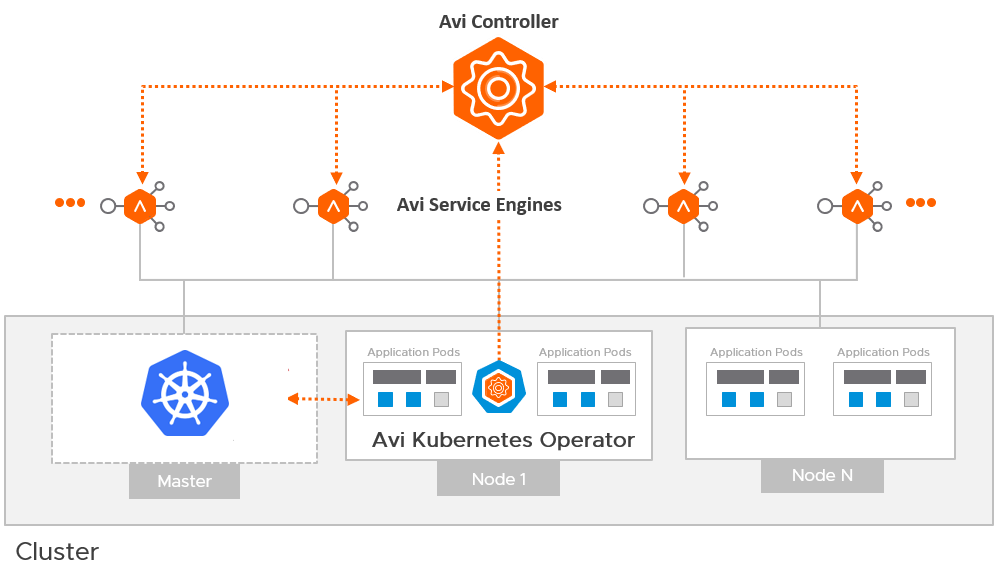
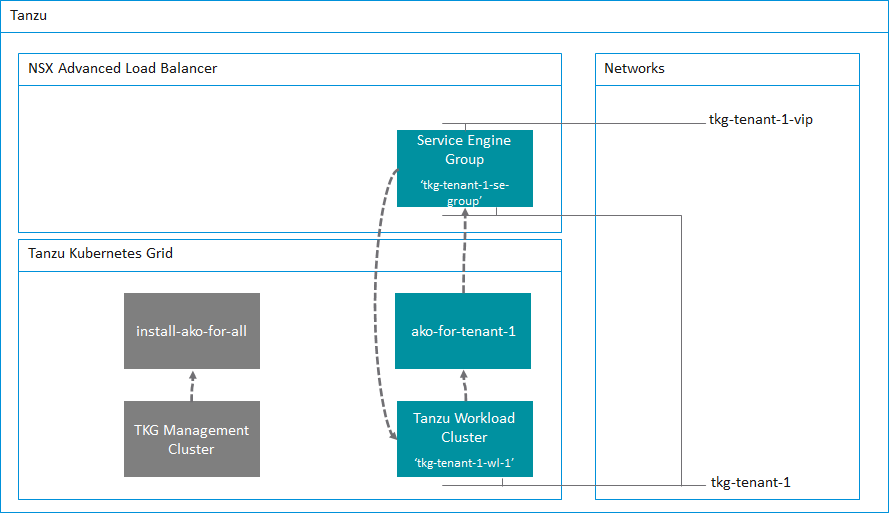
In the previous post, I highlighted the key updates that the TKG 2.3 release had towards multi availability zone enabled clusters. The previous post discussed greenfield Day-0 deployments of TKG clusters using multi AZs. This post will focus more on Day-2 operations, such as how to enable AZs for already deployed clusters that were not AZ enabled. For example, you already deployed clusters with an older version of TKG that did not bring generally available support for the multi-AZ feature.
Enabling multi-AZ for clusters initially deployed without AZs
To enable multi-AZ for a cluster that was initially deployed without AZs, you can follow the procedure below. Note that this is for a workload cluster and not a management cluster. To enable this for a management cluster, just add the tkg-system namespace and change the name of the cluster to the management cluster.
We’ve made it very easy to do Day-2 operations, since the AZs are just labels, and if you’re already familiar with Kubernetes labels, its a simple operation of adding the label to the controlPlaneZoneMatchingLabels key.
Note that the labels needs to be relevant to the file vsphere-zones.yaml labels, just apply this file to the TKG management cluster. My example is below:
---
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: VSphereDeploymentZone
metadata:
name: az-1
labels:
region: cluster
az: az-1
spec:
server: vcenter.vmwire.com
failureDomain: az-1
placementConstraint:
resourcePool: tkg-vsphere-workload
folder: tkg-vsphere-workload
---
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: VSphereDeploymentZone
metadata:
name: az-2
labels:
region: cluster
az: az-2
spec:
server: vcenter.vmwire.com
failureDomain: az-2
placementConstraint:
resourcePool: tkg-vsphere-workload
folder: tkg-vsphere-workload
---
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: VSphereDeploymentZone
metadata:
name: az-3
labels:
region: cluster
az: az-3
spec:
server: vcenter.vmwire.com
failureDomain: az-3
placementConstraint:
resourcePool: tkg-vsphere-workload
folder: tkg-vsphere-workload
Control Plane nodes
When ready, run the command below against the TKG Management Cluster context to set the label for control plane nodes of the TKG cluster named tkg-cluster.
kubectl get cluster tkg-cluster -o json | jq '.spec.topology.variables |= map(if .name == "controlPlaneZoneMatchingLabels" then .value = {"region": "cluster"} else . end)'| kubectl replace -f -
You should receive the following response.
cluster.cluster.x-k8s.io/tkg-cluster replaced
You can check that the cluster status to ensure that the failure domain has been updated as expected.
kubectl get cluster tkg-cluster -o json | jq -r '.status.failureDomains | to_entries[].key'
The response would look something like
Next we patch the KubeAdmControlPlane with rolloutAfter to trigger an update of controlplane node(s).
kubectl patch kcp tkg-cluster-f2km7 --type merge -p "{\"spec\":{\"rolloutAfter\":\"$(date +'%Y-%m-%dT%TZ')\"}}"
You should see vCenter start to clone new control plane nodes, and when the nodes start, they will be placed in an AZ. You can also check with the command below.
kubectl get machines -o json | jq -r '[.items[] | {name:.metadata.name, failureDomain:.spec.failureDomain}]'
As nodes are started and join the cluster, they will get placed into the right AZ.
[
{
"name": "tkg-cluster-f2km7-2kwgs",
"failureDomain": null
},
{
"name": "tkg-cluster-f2km7-6pgmr",
"failureDomain": null
},
{
"name": "tkg-cluster-f2km7-cqndc",
"failureDomain": "az-2"
},
{
"name": "tkg-cluster-f2km7-pzqwx",
"failureDomain": null
},
{
"name": "tkg-cluster-md-0-j6c24-6c8c9d45f7xjdchc-97q57",
"failureDomain": null
},
{
"name": "tkg-cluster-md-1-nqvsf-55b5464bbbx4xzkd-q6jhq",
"failureDomain": null
},
{
"name": "tkg-cluster-md-2-srr2c-77cc694688xcx99w-qcmwg",
"failureDomain": null
}
]
And after a few minutes…
[
{
"name": "tkg-cluster-f2km7-2kwgs",
"failureDomain": null
},
{
"name": "tkg-cluster-f2km7-4tn6l",
"failureDomain": "az-1"
},
{
"name": "tkg-cluster-f2km7-cqndc",
"failureDomain": "az-2"
},
{
"name": "tkg-cluster-f2km7-w7vs5",
"failureDomain": "az-3"
},
{
"name": "tkg-cluster-md-0-j6c24-6c8c9d45f7xjdchc-97q57",
"failureDomain": null
},
{
"name": "tkg-cluster-md-1-nqvsf-55b5464bbbx4xzkd-q6jhq",
"failureDomain": null
},
{
"name": "tkg-cluster-md-2-srr2c-77cc694688xcx99w-qcmwg",
"failureDomain": null
}
]
Worker nodes
The procedure is almost the same for the worker nodes.
Let’s check the current MachineDeploy topology.
kubectl get cluster tkg-cluster -o=jsonpath='{range .spec.topology.workers.machineDeployments[*]}{"Name: "}{.name}{"\tFailure Domain: "}{.failureDomain}{"\n"}{end}'
The response should be something like this, since this cluster was initially deployed without AZs.
Name: md-0 Failure Domain:
Name: md-1 Failure Domain:
Name: md-2 Failure Domain:
Patch the cluster tkg-cluster with VSphereFailureDomain az-1, az-2 and az-3. In this example, the tkg-cluster cluster plan is prod and has three MachineDeployments. If your tkg-cluster cluster uses the dev plan, then you only need to update 1 MachineDeployment in cluster spec.toplogy.wokers.machineDeployments.
kubectl patch cluster tkg-cluster --type=json -p='[ {"op": "replace", "path": "/spec/topology/workers/machineDeployments/0/failureDomain", "value": "az-1"}, {"op": "replace", "path": "/spec/topology/workers/machineDeployments/1/failureDomain", "value": "az-2"}, {"op": "replace", "path": "/spec/topology/workers/machineDeployments/2/failureDomain", "value": "az-3"}]'
Lets check the MachineDeployment topology now that the change has been made.
kubectl get cluster tkg-cluster -o=jsonpath='{range .spec.topology.workers.machineDeployments[*]}{"Name: "}{.name}{"\tFailure Domain: "}{.failureDomain}{"\n"}{end}'
The response should be something like this, since this cluster was initially deployed without AZs.
Name: md-0 Failure Domain: az-1
Name: md-1 Failure Domain: az-2
Name: md-2 Failure Domain: az-3
vCenter should immediately start deploying new worker nodes, when they start they will be placed into the correct AZs.
You can also check with the command below.
kubectl get machines -o json | jq -r '[.items[] | {name:.metadata.name, failureDomain:.spec.failureDomain}]'
[
{
"name": "tkg-cluster-f2km7-4tn6l",
"failureDomain": "az-1"
},
{
"name": "tkg-cluster-f2km7-cqndc",
"failureDomain": "az-2"
},
{
"name": "tkg-cluster-f2km7-w7vs5",
"failureDomain": "az-3"
},
{
"name": "tkg-cluster-md-0-j6c24-6c8c9d45f7xjdchc-97q57",
"failureDomain": null
},
{
"name": "tkg-cluster-md-0-j6c24-8f6b4f8d5xplqlf-p8d8k",
"failureDomain": "az-1"
},
{
"name": "tkg-cluster-md-1-nqvsf-55b5464bbbx4xzkd-q6jhq",
"failureDomain": null
},
{
"name": "tkg-cluster-md-1-nqvsf-7dc48df8dcx6bs6b-kmj9r",
"failureDomain": "az-2"
},
{
"name": "tkg-cluster-md-2-srr2c-77cc694688xcx99w-qcmwg",
"failureDomain": null
},
{
"name": "tkg-cluster-md-2-srr2c-f466d4484xxc9xz-8sjfn",
"failureDomain": "az-3"
}
]
And after a few minutes…
kubectl get machines -o json | jq -r ‘[.items[] | {name:.metadata.name, failureDomain:.spec.failureDomain}]’
[
{
"name": "tkg-cluster-f2km7-4tn6l",
"failureDomain": "az-1"
},
{
"name": "tkg-cluster-f2km7-cqndc",
"failureDomain": "az-2"
},
{
"name": "tkg-cluster-f2km7-w7vs5",
"failureDomain": "az-3"
},
{
"name": "tkg-cluster-md-0-j6c24-8f6b4f8d5xplqlf-p8d8k",
"failureDomain": "az-1"
},
{
"name": "tkg-cluster-md-1-nqvsf-7dc48df8dcx6bs6b-kmj9r",
"failureDomain": "az-2"
},
{
"name": "tkg-cluster-md-2-srr2c-f466d4484xxc9xz-8sjfn",
"failureDomain": "az-3"
}
]
Update CPI and CSI for topology awareness
We also need to update the CPI and CSI to reflect the support for multi-AZ, note this is only required for Day-2 operations as CSI and CPI topology awareness is automatically done for greenfield clusters.
First, check to see if the machineDeployments have been updated for Failure
In TKG 2.3 with cluster class based clusters, CPI and CSI are managed by Tanzu Packages (pkgi), you can see these by running the following commands:
k get vspherecpiconfigs.cpi.tanzu.vmware.com
k get vspherecsiconfigs.csi.tanzu.vmware.com
First, we need to update the VSphereCPIConfig and add in the k8s-region and k8s-zone into the spec.
k edit vspherecpiconfigs.cpi.tanzu.vmware.com tkg-workload12-vsphere-cpi-package
Add in the region and zone into the spec.
spec:
vsphereCPI:
antreaNSXPodRoutingEnabled: false
mode: vsphereCPI
region: k8s-region
tlsCipherSuites: TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,TLS_ECDHE_ECDSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305,TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384
zone: k8s-zone
Change to the workload cluster context and run this command to check the reconciliation status for VSphereCPIConfig
k get pkgi -n tkg-system tkg-workload12-vsphere-cpi
If it shows anything but Reconcile succeeded, then we need to force the update with a deletion.
k delete pkgi -n tkg-system tkg-workload12-vsphere-cpi
Secondly, we need to update the VSphereCSIConfig and add in the k8s-region and k8s-zone into the spec.
Change back to the TKG Management cluster context and run the following command
k edit vspherecsiconfigs.csi.tanzu.vmware.com tkg-workload12
spec:
vsphereCSI:
config:
datacenter: /home.local
httpProxy: ""
httpsProxy: ""
insecureFlag: false
noProxy: ""
useTopologyCategories: true
region: k8s-region
zone: k8s-zone
mode: vsphereCSI
Delete the csinodes and csinodetopologies to make the change.
Change to the workload cluster context and run the following commands
k delete csinode --all --context tkg-workload12-admin@tkg-workload12
k delete csinodetopologies.cns.vmware.com --all --context tkg-workload12-admin@tkg-workload12
Run the following command to check the reconciliation process
k get pkgi -n tkg-system tkg-workload12-vsphere-csi
We need to delete the CSI pkgi to force the change
k delete pkgi -n tkg-system tkg-workload12-vsphere-csi
We can check that the topology keys are now active with this command
kubectl get csinodes -o jsonpath='{range .items[*]}{.metadata.name} {.spec}{"\n"}{end}'
tkg-workload12-md-0-5j2dw-76bf777bbdx6b4ss-v7fn4 {"drivers":[{"allocatable":{"count":59},"name":"csi.vsphere.vmware.com","nodeID":"4225d4f9-ded1-611b-1fd5-7320ffffbe28","topologyKeys":["topology.csi.vmware.com/k8s-region","topology.csi.vmware.com/k8s-zone"]}]}
tkg-workload12-md-1-69s4n-85b74654fdx646xd-ctrkg {"drivers":[{"allocatable":{"count":59},"name":"csi.vsphere.vmware.com","nodeID":"4225ff47-9c82-b377-a4a2-d3ea15bce5aa","topologyKeys":["topology.csi.vmware.com/k8s-region","topology.csi.vmware.com/k8s-zone"]}]}
tkg-workload12-md-2-h2p9p-5f85887b47xwzcpq-7pgc8 {"drivers":[{"allocatable":{"count":59},"name":"csi.vsphere.vmware.com","nodeID":"4225b76d-ef40-5a7f-179a-31d804af969c","topologyKeys":["topology.csi.vmware.com/k8s-region","topology.csi.vmware.com/k8s-zone"]}]}
tkg-workload12-x2jb5-6nt2b {"drivers":[{"allocatable":{"count":59},"name":"csi.vsphere.vmware.com","nodeID":"4225ba85-53dc-56fd-3e9c-5ce609bb08d3","topologyKeys":["topology.csi.vmware.com/k8s-region","topology.csi.vmware.com/k8s-zone"]}]}
tkg-workload12-x2jb5-7sl8j {"drivers":[{"allocatable":{"count":59},"name":"csi.vsphere.vmware.com","nodeID":"42251a1c-871c-5826-5a45-a6747c181962","topologyKeys":["topology.csi.vmware.com/k8s-region","topology.csi.vmware.com/k8s-zone"]}]}
tkg-workload12-x2jb5-mmhvb {"drivers":[{"allocatable":{"count":59},"name":"csi.vsphere.vmware.com","nodeID":"42257d5a-daab-2ba6-dfb7-aa75f4063250","topologyKeys":["topology.csi.vmware.com/k8s-region","topology.csi.vmware.com/k8s-zone"]}]}
Thats it! We’ve successfully updated an already deployed cluster without AZs to now be able to use AZs for pod placement and PVC placement with topology awareness.