Container Service Extension 4 was released recently. This post aims to help ease the setup of CSE 4.0 as it has a different deployment model using the Solutions framework instead of deploying the CSE appliance into the traditional Management cluster concept used by service providers to run VMware management components such as vCenter, NSX-T Managers, Avi Controllers and other management systems.
Step 1 – Create a CSE Service Account
Perform these steps using the administrator@system account or an equivalent system administrator role.
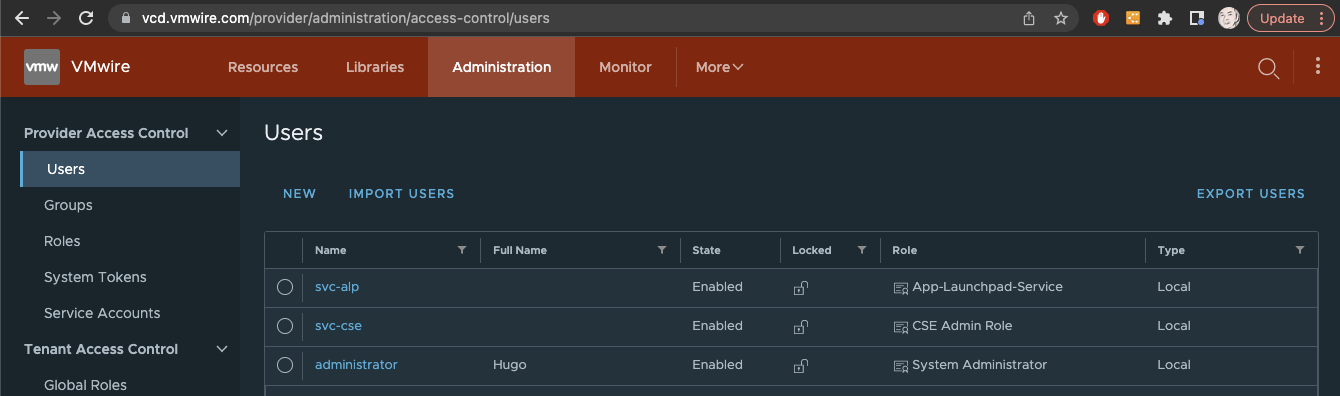
Setup a Service Account in the Provider (system) organization with the role CSE Admin Role.
In my environment I created a user to use as a service account named svc-cse. You’ll notice that this user has been assigned the CSE Admin Role.
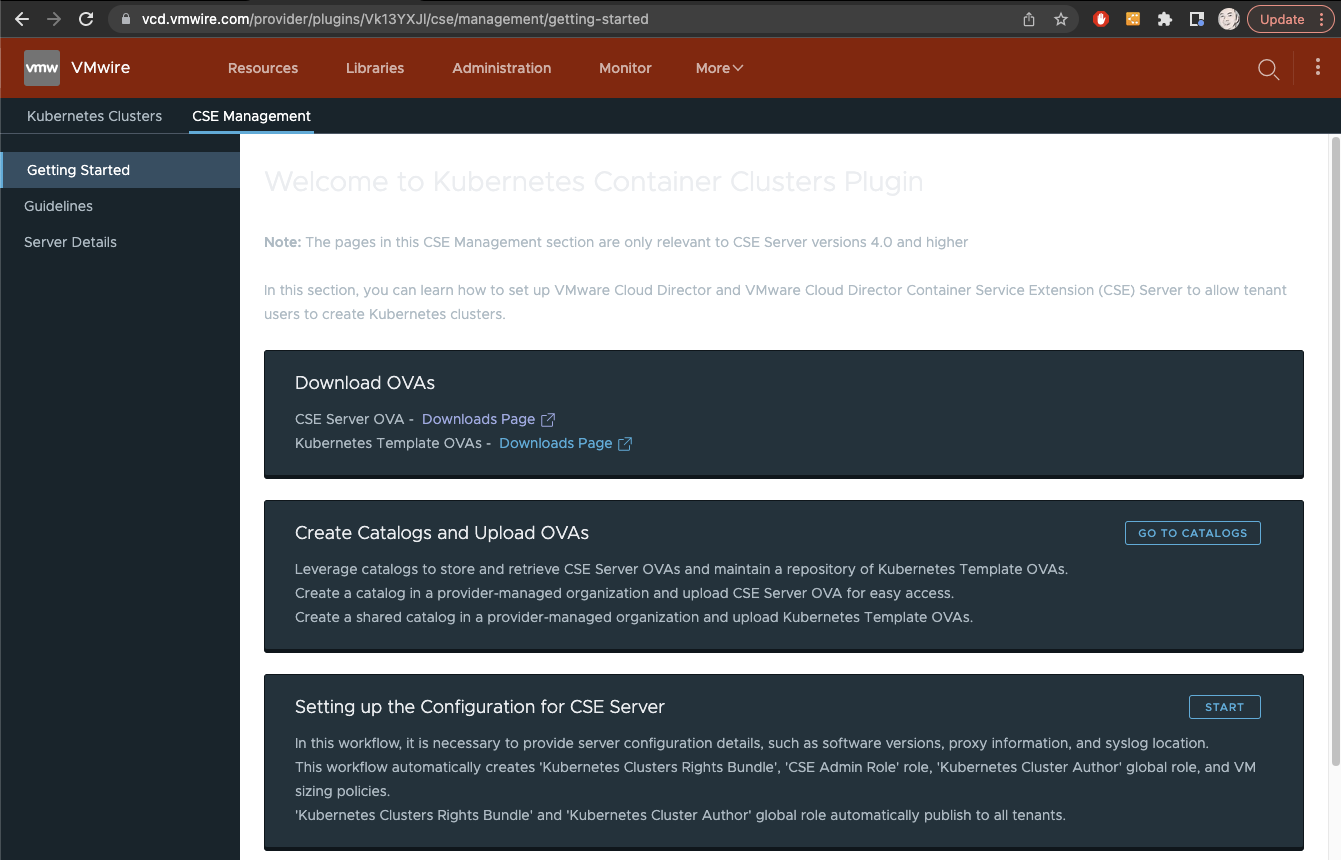
The CSE Admin Role is created automatically by CSE when you use the CSE Management UI as a Provider administrator, just do these steps using the administrator@system account.
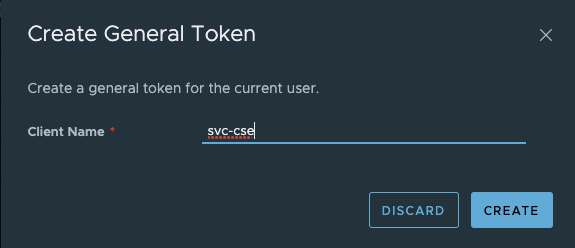
Step 2 – Create a token for the Service Account
Log out of VCD and log back into the Provider organization as the service account you created in Step 1 above. Once logged in, it should look like the following screenshot, notice that the svc-cse user is logged into the Provider organization.
Click on the downward arrow at the top right of the screen, next to the user svc-cse and select User Preferences.
Under Access Tokens, create a new token and copy the token to a safe place. This is what you use to deploy the CSE appliance later.
Log out of VCD and log back in as adminstrator@system to the Provider organization.
Step 3 – Deploy CSE appliance
Create a new tenant Organization where you will run CSE. This new organization is dedicated to VCD extensions such as CSE and is managed by the service provider.
For example you can name this new organization something like “solutions-org“. Create an Org VDC within this organization and also the necessary network infrastructure such as a T1 router and an organization network with internet access.
Still logged into the Provider organization, open another tab by clicking on the Open in Tenant Portal link to your “solutions-org” organization. You must deploy the CSE vApp as a Provider.
Now you can deploy the CSE vApp.
Use the Add vApp From Catalog workflow.
Accept the EULA and continue with the workflow.
When you get the Step 8 of the Create vApp from Template, ensure that you setup the OVF properties like my screenshot below:
The important thing to note is to ensure that you are using the correct service account username and use the token from Step 2 above.
Also since you must have the service account in the Provider organization, leave the default system organization for CSE service account’s org.
The last value is very important, it must by set to the tenant organization that will run the CSE appliance, in our case it is the “solutions-org” org.
Once the OVA is deployed you can boot it up or if you want to customize the root password then do so before you start the vApp. If not, the default credentials are root and vmware.
Rights required for deploying TKG clusters
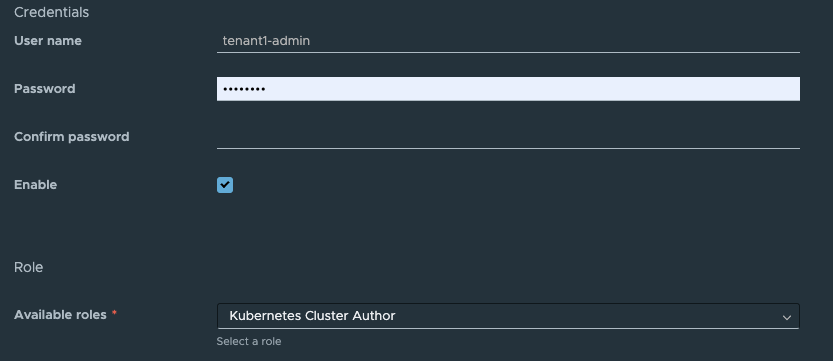
Ensure that the user that is logged into a tenant organization has the correct rights to deploy a TKG cluster. This user must have at a minimum the rights in the Kubernetes Cluster Author Global Role.
App LaunchPad
You’ll also need to upgrade App Launchpad to the latest version alp-2.1.2-20764259 to support CSE 4.0 deployed clusters.
Also ensure that the App-Launchpad-Service role has the rights to manage CAPVCD clusters.
Otherwise you may encounter the following issue:
VCD API Protected by Web Application Firewalls
If you are using a web application firewall (WAF) in front of your VCD cells and you are blocking access to the provider side APIs. You will need to add the SNAT IP address of the T1 from the solutions-org into the WAF whitelist.
The CSE appliance will need access to the VCD provider side APIs.
I wrote about using a WAF in front of VCD in the past to protect provider side APIs. You can read those posts here and here.
I’ve been experimenting with the VMware Cloud Director, Container Service Extension and App Launchpad applications and wanted to test if these applications would run in Kubernetes.
The short answer is yes!
I’ve been experimenting with the VMware Cloud Director, Container Service Extension and App Launchpad applications and wanted to test if these applications would run in Kubernetes.
The short answer is yes!
I initially deployed these apps as a standalone Docker container to see if they would run as a container. I wanted to eventually get them to run in a Kubernetes cluster to benefit from all the goodies that Kubernetes provides.
Packaging the apps wasn’t too difficult, just needed patience and a lot of Googling. The process was as follows:
run a Docker image of a Linux image, CentOS for VCD and Photon for ALP and CSE.
prepare all the pre-requisites, such as yum update and tdnf update.
commit the image to a Harbor registry
build a Helm chart to deploy the applications using the images and then create a shell script that is run when the image starts to install and run the applications.
Well, its not that simple but you can take a look at the code for all three Helm Charts on my Github or pull them from my public Harbor repository.
The values.yaml file is the only file you’ll need to edit, just update to suit your environment.
# Default values for vmware-cloud-director.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
replicaCount: 1
installFirstCell:
enabled: true
installAdditionalCell:
enabled: false
storageClass: iscsi
pvcCapacity: 2Gi
vcdNfs:
server: 10.92.124.20
mountPath: /mnt/nvme/vcd-k8s
vcdSystem:
user: administrator
password: Vmware1!
email: admin@domain.local
systemName: VCD
installationId: 1
postgresql:
dbHost: postgresql.vmware-cloud-director.svc.cluster.local
dbName: vcloud
dbUser: vcloud
dbPassword: Vmware1!
# Availability zones in deployment.yaml are setup for TKG and must match VsphereFailureDomain and VsphereDeploymentZones
availabilityZones:
enabled: false
httpsService:
type: LoadBalancer
port: 443
consoleProxyService:
port: 8443
publicAddress:
uiBaseUri: https://vcd-k8s.vmwire.com
uiBaseHttpUri: http://vcd-k8s.vmwire.com
restapiBaseUri: https://vcd-k8s.vmwire.com
restapiBaseHttpUri: http://vcd-k8s.vmwire.com
consoleProxy: vcd-vmrc.vmwire.com
tls:
certFullChain: |-
-----BEGIN CERTIFICATE-----
wildcard certificate
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
intermediate certificate
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
root certificate
-----END CERTIFICATE-----
certKey: |-
-----BEGIN PRIVATE KEY-----
wildcard certificate private key
-----END PRIVATE KEY-----
The installation process is quite fast, less than three minutes to get the first pod up and running and two minutes for each subsequent pod. That means a VCD multi-cell system up and running in less than ten minutes.
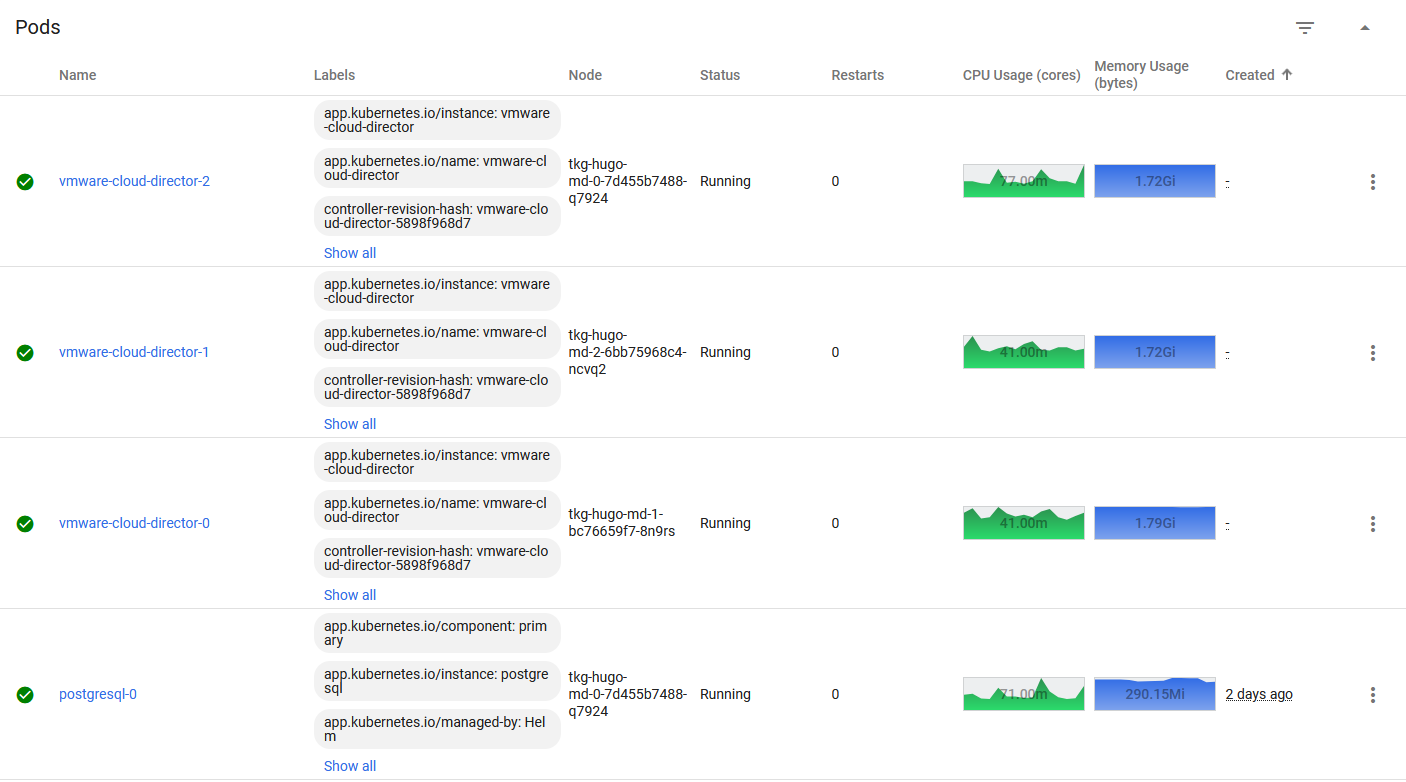
I’ve deployed VCD as a StatefulSet, and have three replicas. Since the replica is set to three, three VCD “Pods” are deployed, in the old world these would be the cells. Here you can see three pods running which would provide both load balancing and high-availability. The other pod is the PostgreSQL database that these cells use. You should also be able to see that Kubernetes has scheduled each pod on a different worker node. I have three worker nodes in this Kubernetes cluster.
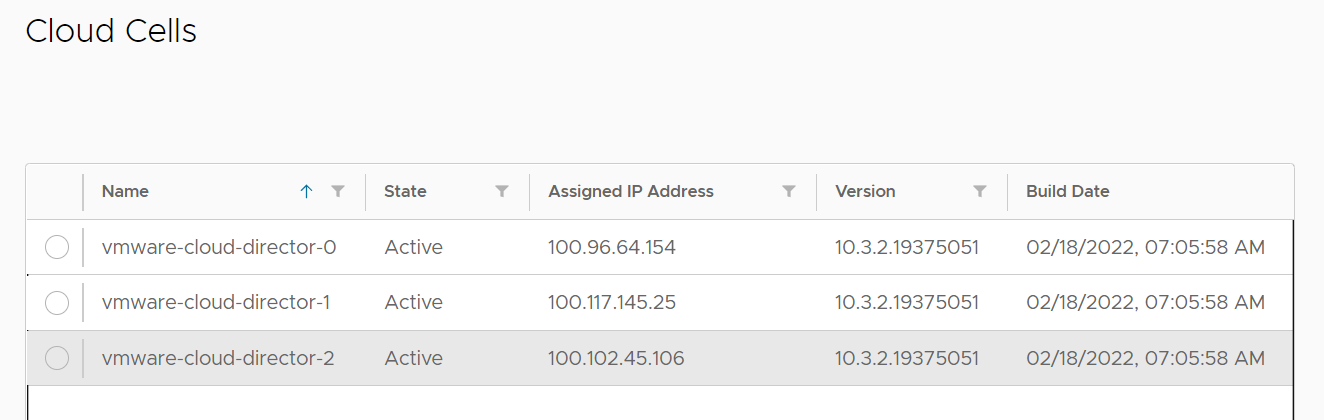
Below is the view in VCD of the three cells.
The StatefulSet also has a LoadBalancer service configured for performing the load balancing of the HTTP and Console Proxy traffic on TCP 443 and TCP 8443 respectively.
You can see the LoadBalancer service has configured the services for HTTP and Console Proxy. Note, that this is done automatically by Kubernetes using a manifest in the Helm Chart.
Migrating an existing VCD instance to Kubernetes
If you want to migrate an existing instance to Kubernetes, then use this post here.
How to install: Update values.yaml and then run helm install container-service-extension oci://harbor.vmwire.com/library/container-service-extension --version 0.2.0 -n container-service-extension
Here’s CSE running as a pod in Kubernetes. Since CSE is a stateless application, I’ve configured it to run as a Deployment.
CSE also does not need a database as it purely communicates with VCD through a message bus such as MQTT or RabbitMQ. Additionally no external access to CSE is required as this is done via VCD, so no load balancer is needed either.
You can see that when CSE is idle it only needs 1 milicore of CPU and 102Mib of RAM. This is so much better in terms of resource requirements than running CSE in a VM. This is one of the advantages of running pods vs VMs. Pods will use considerably fewer resources than VMs.
How to install: Update values.yaml and then run helm install app-launchpad oci://harbor.vmwire.com/library/app-launchpad --version 0.4.0 -n app-launchpad
The values.yaml file is the only file you’ll need to edit, just update to suit your environment.
# Default values for app-launchpad.
# This is a YAML-formatted file.
# Declare variables to be passed into your templates.
alpConnect:
saUser: "svc-alp"
saPass: Vmware1!
url: https://vcd-k8s.vmwire.com
adminUser: administrator@system
adminPass: Vmware1!
mqtt: true
eula: accept
# If you accept the EULA then type "accept" in the EULA key value to install ALP. You can fine the EULA in the README.md file.
I’ve already written an article about ALP here. That article contains a lot more details so I’ll share a few screenshots below for ALP.
Just like CSE, ALP is a stateless application and is deployed as a Deployment. ALP also does not require external access through a load balancer as it too communicates with VCD using the MQTT or RabbitMQ message bus.
You can see that ALP when idle requires just 3 milicores of CPU and 400 Mib of RAM.
ALP can be deployed with multiple instances to provide load balancer and high availability. This is done by deploying RabbitMQ and connecting ALP and VCD to the same exchange. VCD does not support multiple instances of ALP if MQTT is used.
When RabbitMQ is configured, then ALP can be scaled by changing the Deployment number of replicas to two or more. Kubernetes would then deploy additional pods with ALP.
Velero (formerly Heptio Ark) gives you tools to back up and restore your Kubernetes cluster resources and persistent volumes. You can run Velero with a cloud provider or on-premises.
This works with any Kubernetes cluster, including Tanzu Kubernetes Grid and Kubernetes clusters deployed with Container Service Extension with VMware Cloud Director.
This solution can be used for air-gapped environments where the Kuberenetes clusters do not have Internet access and cannot use public services such as Amazon S3, or Tanzu Mission Control Data Protection. These services are SaaS services which are pretty much out of bounds in air-gapped environments.
Overview
Velero (formerly Heptio Ark) gives you tools to back up and restore your Kubernetes cluster resources and persistent volumes. You can run Velero with a cloud provider or on-premises. Velero lets you:
Take backups of your cluster and restore in case of loss.
Migrate cluster resources to other clusters.
Replicate your production cluster to development and testing clusters.
Velero consists of:
A server that runs on your Kubernetes cluster
A command-line client that runs locally
Velero works with any Kubernetes cluster, including Tanzu Kubernetes Grid and Kubernetes clusters deployed using Container Service Extension with VMware Cloud Director.
This solution can be used for air-gapped environments where the Kubernetes clusters do not have Internet access and cannot use public services such as Amazon S3, or Tanzu Mission Control Data Protection. These services are SaaS services which are pretty much out of bounds in air-gapped environments.
Install Velero onto your workstation
Download the latest Velero release for your preferred operating system, this is usually where you have your kubectl tools.
If you want to enable bash auto completion, please follow this guide.
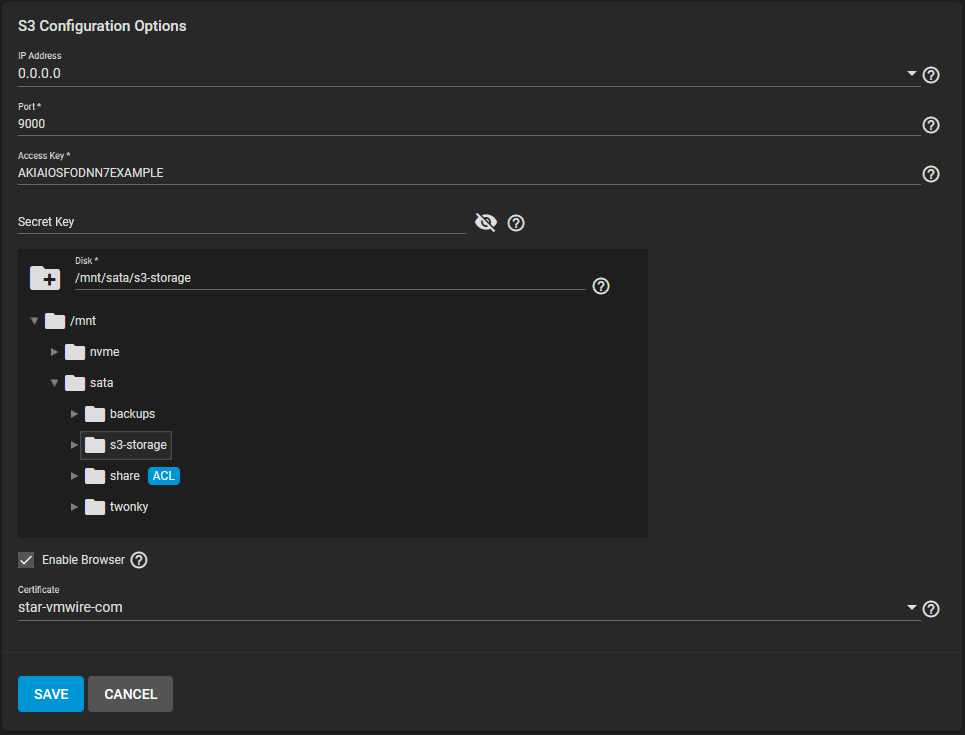
Setup an S3 service and bucket
I’m using TrueNAS’ S3 compatible storage in my lab. TrueNAS is an S3 compliant object storage system and is incredibly easy to setup. You can use other S3 compatible object stores such as Amazon S3. A full list of supported providers can be found here.
Follow these instructions to setup S3 on TrueNAS.
Add certificate, go to System, Certificates
Add, Import Certificate, copy and paste cert.pem and cert.key
Storage, Pools, click on the three dots next to the Pools that will hold the S3 root bucket.
Add a Dataset, give it a name such as s3-storage
Services, S3, click on pencil icon.
Setup like the example below.
Setup the access key and secret key for this configuration.
Update DNS to point to s3.vmwire.com to 10.92.124.20 (IP of TrueNAS). Note that this FQDN and IP address needs to be accessible from the Kubernetes worker nodes. For example, if you are installing Velero onto Kubernetes clusters in VCD, the worker nodes on the Organization network need to be able to route to your S3 service. If you are a service provider, you can place your S3 service on the services network that is accessible by all tenants in VCD.
Setup the connection to your S3 service using the access key and secret key.
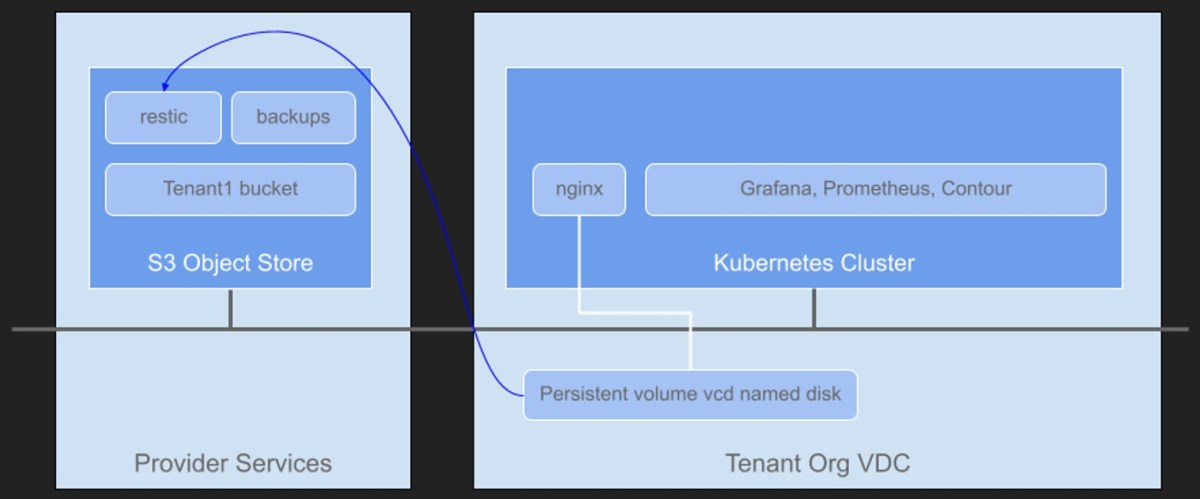
Create a new bucket to store some backups. If you are using Container Service Extension with VCD, create a new bucket for each Tenant organization. This ensures multi-tenancy is maintained. I’ve create a new bucket named tenant1 which corresponds to one of my tenant organizations in my VCD environment.
Install Velero into the Kubernetes cluster
You can use the velero-plugin-for-aws and the AWS provider with any S3 API compatible system, this includes TrueNAS, Cloudian Hyperstore etc.
Setup a file with your access key and secret key details, the file is named credentials-velero.
vi credentials-velero
[default]
aws_access_key_id = AKIAIOSFODNN7EXAMPLE
aws_secret_access_key = wJalrXUtnFEMIK7MDENGbPxRfiCYEXAMPLEKEY
Change your Kubernetes context to the cluster that you want to enable for Velero backups. The Velero CLI will connect to your Kubernetes cluster and deploy all the resources for Velero.
To install Restic, use the --use-restic flag in the velero install command. See the install overview for more details on other flags for the install command.
velero install --use-restic
When using Restic on a storage provider that doesn’t have Velero support for snapshots, the --use-volume-snapshots=false flag prevents an unused VolumeSnapshotLocation from being created on installation. The VCD CSI provider does not provide native snapshot capability, that’s why using Restic is a good option here.
I’ve enabled the default behavior to include all persistent volumes to be included in pod backups enabled on all Velero backups running the velero install command with the --default-volumes-to-restic flag. Refer install overview for details.
Specify the bucket with the --bucket flag, I’m using tenant1 here to correspond to a VCD tenant that will have its own bucket for storing backups in the Kubernetes cluster.
For the --backup-location-config flag, configure you settings like mine, and use the s3Url flag to point to your S3 object store, if you don’t use this Velero will use AWS’ S3 public URIs.
NAME READY STATUS RESTARTS AGE
pod/restic-x6r69 1/1 Running 0 49m
pod/velero-7bc4b5cd46-k46hj 1/1 Running 0 49m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/restic 1 1 1 1 1 <none> 49m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/velero 1/1 1 1 49m
NAME DESIRED CURRENT READY AGE
replicaset.apps/velero-7bc4b5cd46 1 1 1 49m
Kubeapps is a web-based UI for deploying and managing applications in Kubernetes clusters. This guide shows how you can deploy Kubeapps into your TKG clusters deployed in VMware Cloud Director.
Kubeapps is a web-based UI for deploying and managing applications in Kubernetes clusters. This guide shows how you can deploy Kubeapps into your TKG clusters deployed in VMware Cloud Director.
With Kubeapps you can:
Customize deployments through an intuitive, form-based user interface
Inspect, upgrade and delete applications installed in the cluster
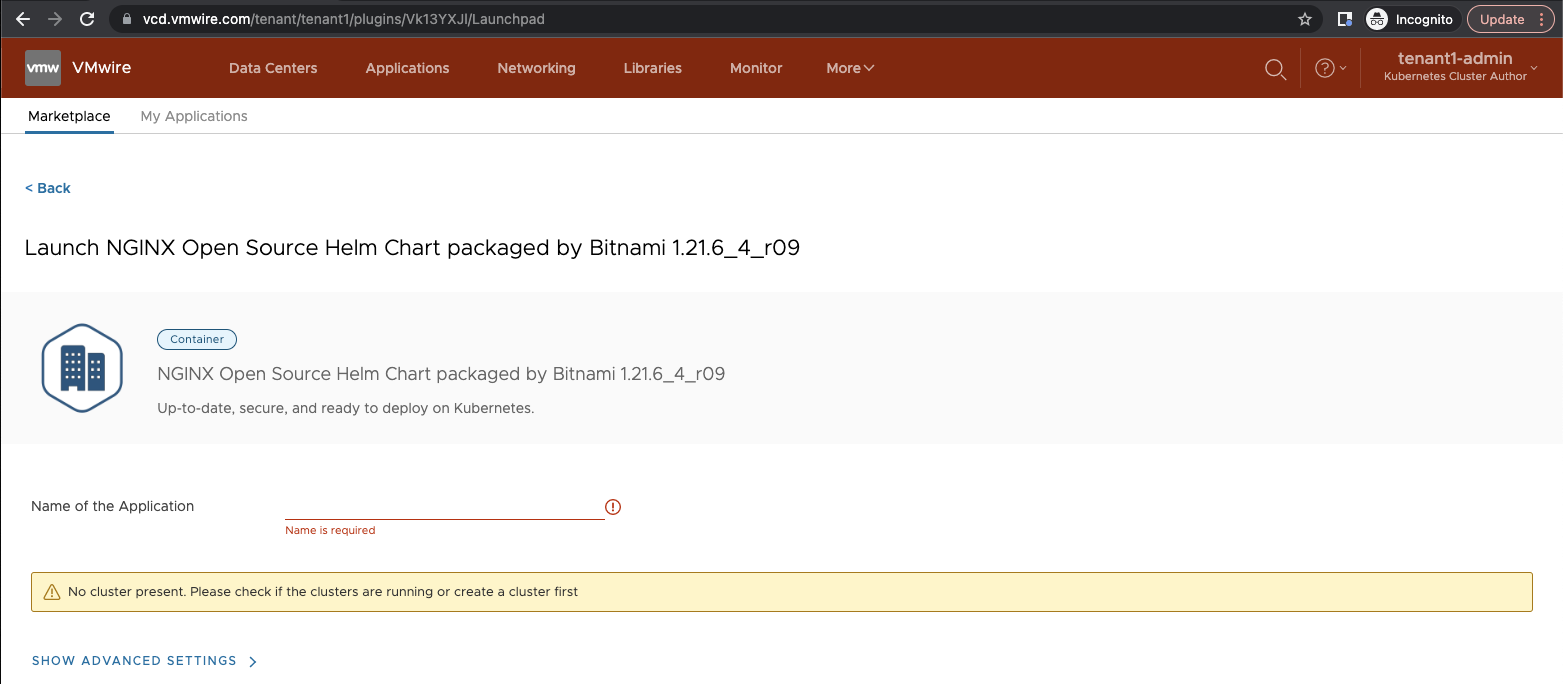
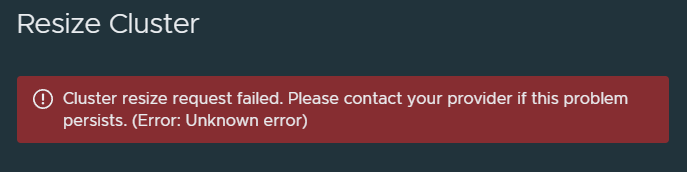
When trying to resize a TKGm cluster with CSE, you might encounter this error below:
Cluster resize request failed. Please contact your provider if this problem persists. (Error: Unknown error)
This post shows how you can use the vcd cse cli to workaround this problem.
When trying to resize a TKGm cluster with CSE in the VCD UI, you might encounter this error below:
Cluster resize request failed. Please contact your provider if this problem persists. (Error: Unknown error)
Checking the logs in ~/.cse-logs there are no logs that show what the error is. It appears to be an issue with the Container UI Plugin for CSE 3.1.0.
If you review the console messages in Chrome’s developer tools you might see something like the following:
TypeError: Cannot read properties of null (reading 'length')
at getFullSpec (https://vcd.vmwire.com/tenant/tenant1/uiPlugins/80134fc9-86e1-41db-9d02-b02d5e9e1e3c/ca5642fa-7186-4da2-b273-2dbd3451fd50/bundle.js:1:170675)
at resizeCseCluster
This post shows how you can use the vcd cse cli to workaround this problem.
Using the vcd cse cli to resize a TKGm cluster
First log into the CSE appliance or somewhere with vcd cse cli installed
Then log into the VCD Org that has the cluster that you want to resize with a user with the role with the cse:nativecluster rights bundle.
Change the workers: count to your new desired number of workers.
Save this file as update_my_cluster.yaml
Update the cluster with this command
vcd cse cluster apply update_my_cluster.yaml
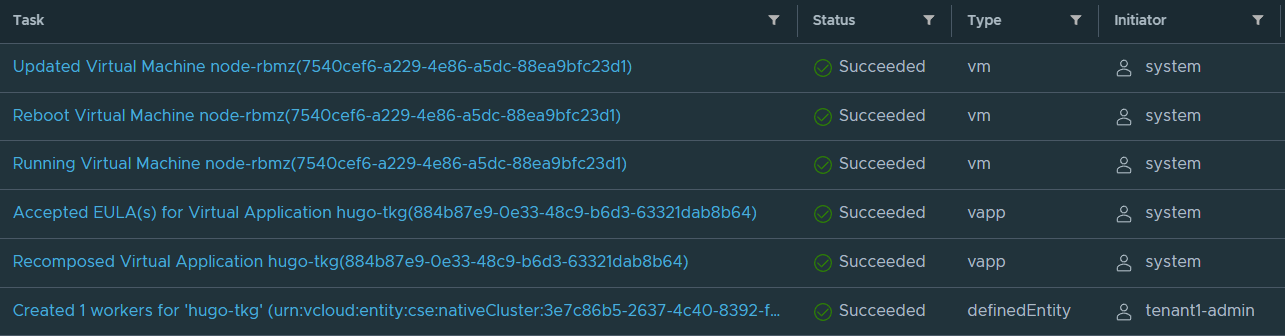
You’ll notice that CSE will deploy another worker node into the same vApp and after a few minutes your TKGm cluster will have another node added to it.
root@photon-manager [ ~/.kube ]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
mstr-zcn7 Ready control-plane,master 14m v1.20.5+vmware.2
node-7swy Ready <none> 10m v1.20.5+vmware.2
node-90sb Ready <none> 12m v1.20.5+vmware.2
root@photon-manager [ ~/.kube ]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
mstr-zcn7 Ready control-plane,master 22m v1.20.5+vmware.2
node-7swy Ready <none> 17m v1.20.5+vmware.2
node-90sb Ready <none> 19m v1.20.5+vmware.2
node-rbmz Ready <none> 43s v1.20.5+vmware.2
Viewing client logs
The vcd cse cli commands are client side, to enable logging for this do the following
Run this command in the CSE appliance or on your workstation that has the vcd cse cli installed.
CSE_CLIENT_WIRE_LOGGING=True
View the logs by using this command
tail -f cse-client-debug.log
A couple of notes
The vcd cse cluster resize command is not enabled if your CSE server is using legacy_mode: false. You can read up on this in this link.
Therefore, the only way to resize a cluster is to update it using the vcd cse cluster apply command. The apply command supports the following:
apply a configuration to a cluster resource by filename. The resource will be created if it does not exist. (The command can be used to create the cluster, scale-up/down worker count, scale-up NFS nodes, upgrade the cluster to a new K8s version.
CSE 3.1.1 can only scale-up a TKGm cluster, it does not support scale-down yet.