Overview
Velero (formerly Heptio Ark) gives you tools to back up and restore your Kubernetes cluster resources and persistent volumes. You can run Velero with a cloud provider or on-premises. Velero lets you:
- Take backups of your cluster and restore in case of loss.
- Migrate cluster resources to other clusters.
- Replicate your production cluster to development and testing clusters.
Velero consists of:
- A server that runs on your Kubernetes cluster
- A command-line client that runs locally
Velero works with any Kubernetes cluster, including Tanzu Kubernetes Grid and Kubernetes clusters deployed using Container Service Extension with VMware Cloud Director.
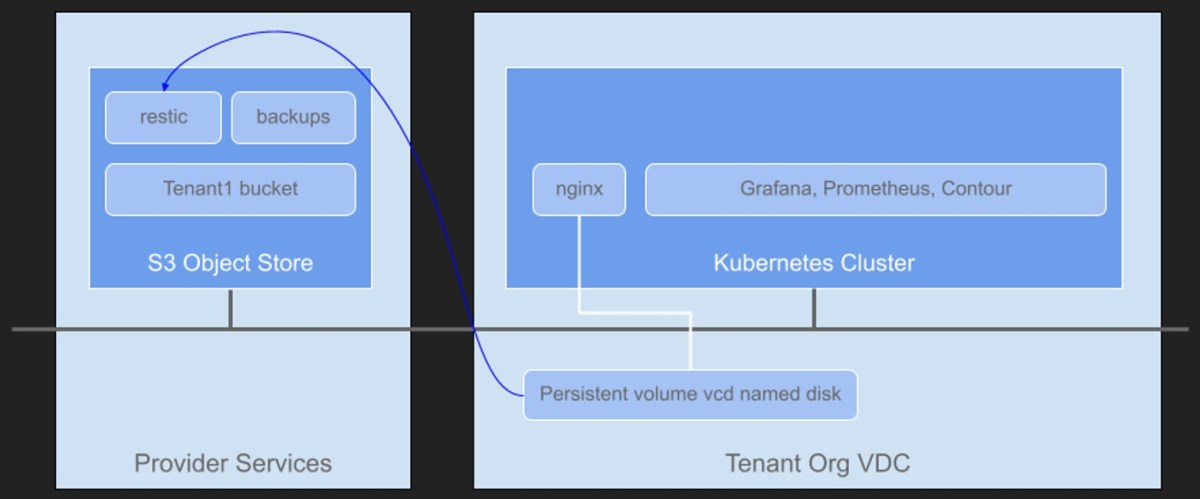
This solution can be used for air-gapped environments where the Kubernetes clusters do not have Internet access and cannot use public services such as Amazon S3, or Tanzu Mission Control Data Protection. These services are SaaS services which are pretty much out of bounds in air-gapped environments.

Install Velero onto your workstation
Download the latest Velero release for your preferred operating system, this is usually where you have your kubectl tools.
https://github.com/vmware-tanzu/velero/releases
Extract the contents.
tar zxvf velero-v1.8.1-linux-amd64.tar.gzYou’ll see a folder structure like the following.
ls -l
total 70252
-rw-r----- 1 phanh users 10255 Mar 10 09:45 LICENSE
drwxr-x--- 4 phanh users 4096 Apr 11 08:40 examples
-rw-r----- 1 phanh users 15557 Apr 11 08:52 values.yaml
-rwxr-x--- 1 phanh users 71899684 Mar 15 02:07 velero
Copy the velero binary to the /usr/local/bin location so it is usable from anywhere.
sudo cp velero /usr/local/bin/velero
sudo chmod +x /usr/local/bin/velero
sudo chmod 755 /usr/local/bin/veleroIf you want to enable bash auto completion, please follow this guide.
Setup an S3 service and bucket
I’m using TrueNAS’ S3 compatible storage in my lab. TrueNAS is an S3 compliant object storage system and is incredibly easy to setup. You can use other S3 compatible object stores such as Amazon S3. A full list of supported providers can be found here.
Follow these instructions to setup S3 on TrueNAS.
- Add certificate, go to System, Certificates
- Add, Import Certificate, copy and paste cert.pem and cert.key
- Storage, Pools, click on the three dots next to the Pools that will hold the S3 root bucket.
- Add a Dataset, give it a name such as s3-storage
- Services, S3, click on pencil icon.
- Setup like the example below.
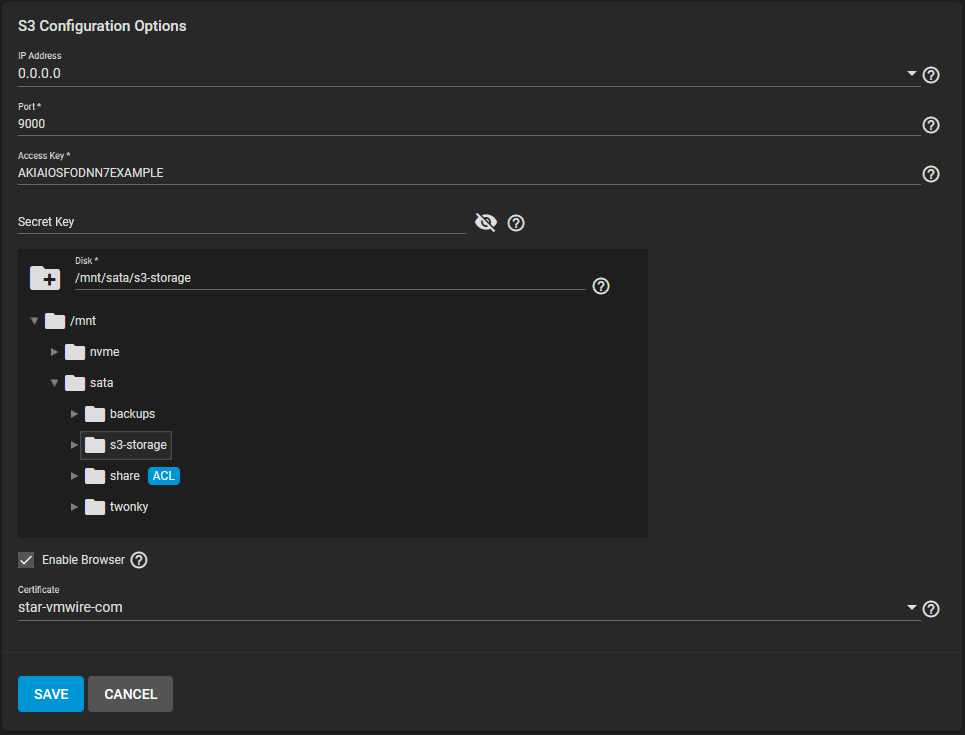
Setup the access key and secret key for this configuration.
access key: AKIAIOSFODNN7EXAMPLE
secret key: wJalrXUtnFEMIK7MDENGbPxRfiCYEXAMPLEKEY
Update DNS to point to s3.vmwire.com to 10.92.124.20 (IP of TrueNAS). Note that this FQDN and IP address needs to be accessible from the Kubernetes worker nodes. For example, if you are installing Velero onto Kubernetes clusters in VCD, the worker nodes on the Organization network need to be able to route to your S3 service. If you are a service provider, you can place your S3 service on the services network that is accessible by all tenants in VCD.
Test access
Download and install the S3 browser tool https://s3-browser.en.uptodown.com/windows
Setup the connection to your S3 service using the access key and secret key.

Create a new bucket to store some backups. If you are using Container Service Extension with VCD, create a new bucket for each Tenant organization. This ensures multi-tenancy is maintained. I’ve create a new bucket named tenant1 which corresponds to one of my tenant organizations in my VCD environment.
Install Velero into the Kubernetes cluster
You can use the velero-plugin-for-aws and the AWS provider with any S3 API compatible system, this includes TrueNAS, Cloudian Hyperstore etc.
Setup a file with your access key and secret key details, the file is named credentials-velero.
vi credentials-velero
[default]
aws_access_key_id = AKIAIOSFODNN7EXAMPLE
aws_secret_access_key = wJalrXUtnFEMIK7MDENGbPxRfiCYEXAMPLEKEY
Change your Kubernetes context to the cluster that you want to enable for Velero backups. The Velero CLI will connect to your Kubernetes cluster and deploy all the resources for Velero.
velero install \
--use-restic \
--default-volumes-to-restic \
--use-volume-snapshots=false \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.4.0 \
--bucket tenant1 \
--backup-location-config region=default,s3ForcePathStyle="true",s3Url=https://s3.vmwire.com:9000 \
--secret-file ./credentials-veleroTo install Restic, use the --use-restic flag in the velero install command. See the install overview for more details on other flags for the install command.
velero install --use-restic
When using Restic on a storage provider that doesn’t have Velero support for snapshots, the --use-volume-snapshots=false flag prevents an unused VolumeSnapshotLocation from being created on installation. The VCD CSI provider does not provide native snapshot capability, that’s why using Restic is a good option here.
I’ve enabled the default behavior to include all persistent volumes to be included in pod backups enabled on all Velero backups running the velero install command with the --default-volumes-to-restic flag. Refer install overview for details.
Specify the bucket with the --bucket flag, I’m using tenant1 here to correspond to a VCD tenant that will have its own bucket for storing backups in the Kubernetes cluster.
For the --backup-location-config flag, configure you settings like mine, and use the s3Url flag to point to your S3 object store, if you don’t use this Velero will use AWS’ S3 public URIs.
A working deployment looks like this
time="2022-04-11T19:24:22Z" level=info msg="Starting Controller" logSource="/go/pkg/mod/github.com/bombsimon/logrusr@v1.1.0/logrusr.go:111" logger=controller.downloadrequest reconciler group=velero.io reconciler kind=DownloadRequest
time="2022-04-11T19:24:22Z" level=info msg="Starting controller" controller=restore logSource="pkg/controller/generic_controller.go:76"
time="2022-04-11T19:24:22Z" level=info msg="Starting controller" controller=backup logSource="pkg/controller/generic_controller.go:76"
time="2022-04-11T19:24:22Z" level=info msg="Starting controller" controller=restic-repo logSource="pkg/controller/generic_controller.go:76"
time="2022-04-11T19:24:22Z" level=info msg="Starting controller" controller=backup-sync logSource="pkg/controller/generic_controller.go:76"
time="2022-04-11T19:24:22Z" level=info msg="Starting workers" logSource="/go/pkg/mod/github.com/bombsimon/logrusr@v1.1.0/logrusr.go:111" logger=controller.backupstoragelocation reconciler group=velero.io reconciler kind=BackupStorageLocation worker count=1
time="2022-04-11T19:24:22Z" level=info msg="Starting workers" logSource="/go/pkg/mod/github.com/bombsimon/logrusr@v1.1.0/logrusr.go:111" logger=controller.downloadrequest reconciler group=velero.io reconciler kind=DownloadRequest worker count=1
time="2022-04-11T19:24:22Z" level=info msg="Starting workers" logSource="/go/pkg/mod/github.com/bombsimon/logrusr@v1.1.0/logrusr.go:111" logger=controller.serverstatusrequest reconciler group=velero.io reconciler kind=ServerStatusRequest worker count=10
time="2022-04-11T19:24:22Z" level=info msg="Validating backup storage location" backup-storage-location=default controller=backup-storage-location logSource="pkg/controller/backup_storage_location_controller.go:114"
time="2022-04-11T19:24:22Z" level=info msg="Backup storage location valid, marking as available" backup-storage-location=default controller=backup-storage-location logSource="pkg/controller/backup_storage_location_controller.go:121"
time="2022-04-11T19:25:22Z" level=info msg="Validating backup storage location" backup-storage-location=default controller=backup-storage-location logSource="pkg/controller/backup_storage_location_controller.go:114"
time="2022-04-11T19:25:22Z" level=info msg="Backup storage location valid, marking as available" backup-storage-location=default controller=backup-storage-location logSource="pkg/controller/backup_storage_location_controller.go:121"
To see all resources deployed, use this command.
k get all -n velero
NAME READY STATUS RESTARTS AGE
pod/restic-x6r69 1/1 Running 0 49m
pod/velero-7bc4b5cd46-k46hj 1/1 Running 0 49m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/restic 1 1 1 1 1 <none> 49m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/velero 1/1 1 1 49m
NAME DESIRED CURRENT READY AGE
replicaset.apps/velero-7bc4b5cd46 1 1 1 49m
Example to test Velero and Restic integration
Please use this link here: https://velero.io/docs/v1.5/examples/#snapshot-example-with-persistentvolumes
You may need to edit the with-pv.yaml manifest if you don’t have a default storage class.
Useful commands
velero get backup-locations
NAME PROVIDER BUCKET/PREFIX PHASE LAST VALIDATED ACCESS MODE DEFAULT
default aws tenant1 Available 2022-04-11 19:26:22 +0000 UTC ReadWrite true
Create a backup example
velero backup create nginx-backup --selector app=nginx
Show backup logs
velero backup logs nginx-backup
Delete a backup
velero delete backup nginx-backup
Show all backups
velero backup get
Backup the VCD PostgreSQL database, see this previous blog post.
velero backup create postgresql --ordered-resources 'statefulsets=vmware-cloud-director/postgresql-primary' --include-namespaces=vmware-cloud-director
Show logs for this backup
velero backup logs postgresql
Describe the postgresql backup
velero backup describe postgresql
Describe volume backups
kubectl -n velero get podvolumebackups -l velero.io/backup-name=nginx-backup -o yaml
apiVersion: v1
items:
- apiVersion: velero.io/v1
kind: PodVolumeBackup
metadata:
annotations:
velero.io/pvc-name: nginx-logs
creationTimestamp: "2022-04-13T17:55:04Z"
generateName: nginx-backup-
generation: 4
labels:
velero.io/backup-name: nginx-backup
velero.io/backup-uid: c92d306a-bc76-47ba-ac81-5b4dae92c677
velero.io/pvc-uid: cf3bdb2f-714b-47ee-876c-5ed1bbea8263
name: nginx-backup-vgqjf
namespace: velero
ownerReferences:
- apiVersion: velero.io/v1
controller: true
kind: Backup
name: nginx-backup
uid: c92d306a-bc76-47ba-ac81-5b4dae92c677
resourceVersion: "8425774"
uid: 1fcdfec5-9854-4e43-8bc2-97a8733ee38f
spec:
backupStorageLocation: default
node: node-7n43
pod:
kind: Pod
name: nginx-deployment-66689547d-kwbzn
namespace: nginx-example
uid: 05afa981-a6ac-4caf-963b-95750c7a31af
repoIdentifier: s3:https://s3.vmwire.com:9000/tenant1/restic/nginx-example
tags:
backup: nginx-backup
backup-uid: c92d306a-bc76-47ba-ac81-5b4dae92c677
ns: nginx-example
pod: nginx-deployment-66689547d-kwbzn
pod-uid: 05afa981-a6ac-4caf-963b-95750c7a31af
pvc-uid: cf3bdb2f-714b-47ee-876c-5ed1bbea8263
volume: nginx-logs
volume: nginx-logs
status:
completionTimestamp: "2022-04-13T17:55:06Z"
path: /host_pods/05afa981-a6ac-4caf-963b-95750c7a31af/volumes/kubernetes.io~csi/pvc-cf3bdb2f-714b-47ee-876c-5ed1bbea8263/mount
phase: Completed
progress:
bytesDone: 618
totalBytes: 618
snapshotID: 8aa5e473
startTimestamp: "2022-04-13T17:55:04Z"
kind: List
metadata:
resourceVersion: ""
selfLink: ""