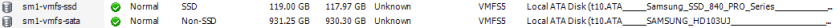[Tongue in cheek. There’s no World Cup on today so I made this. Please don’t take this too seriously.]
A SAN is like a carousel
It provides capacity (just like a carousel) and performance (when the carousel goes around).
People ride on static horses bolted to the carousel and try to enjoy the ride.
This horse is like a LUN. The horse does not know who is riding it.
Everybody travels at the same speed unless you happen to sit on the outside where things go a little bit faster.
The speed is relative to how fast the carousel rotates and how quickly you can get to an outside seat (if you want that extra speed and wind through your hair).
If you want to guarantee an outside seat, you can get to the front of the queue by having a FastPass+.
Get a bigger motor, or increase the speed, the carousel will respond to the required needs.
Everybody experiences the same relative performance even though they may want different things – to go faster or to go slower.
If the motor dies, the carousel is closed.
A Virtual Volume is like a horse
It has a trusting relationship with its rider and the rider with it.
It can roam free on green pastures and prairies.
It can go fast or slow.
It can be large or small.
It can go faster or slower than another horse.
A small horse can carry a small rider.
A large horse can carry a large rider.
A small horse could go faster than a big horse and vice versa.
You can go for a ride with your horse and bring another one just like it. If it gets tired, let it go and jump on the other horse.
It can by put out to stud to make more little foals just like it.
Atlantis USX has some very cool technology which I’ve had the pleasure to ‘play’ with over the past few weeks. In these series of posts I’ll attempt to cover the various technologies within the Atlantis USX stack.
The key technologies in the Atlantis USX In-Memory Data Services are:
Inline IO and Data de-duplication
Content aware IO processing
Compression
Fast Clone
Storage Policies
Thin Provisioning
This post focuses on Inline IO and Data de-duplication (or just dedupe for short) and Fast Clone and how these rich data services enable a hyper converged solution to outperform enterprise storage arrays.
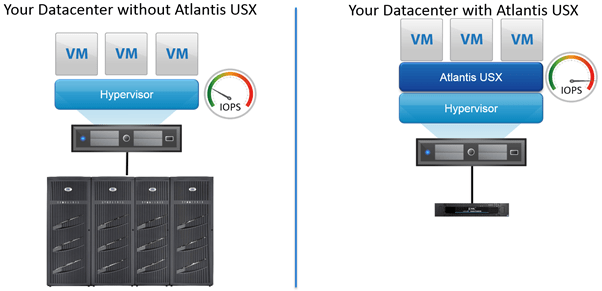
Why would you use Atlantis USX?
The best way to approach this is to look at some use cases: Crazy as it seems, Atlantis USX delivers All-Flash Array performance but also gives five times the capacity of traditional storage arrays. Doing this with 100% software, no hardware appliances, and true software defined storage with software, enabling true web-scale architecture.
The majority of storage vendors today either do one of the other, not both. So you could end up with storage silos where IOPS are provided by an all-flash array and capacity is provided by a traditional SAN.
USX Use Cases
The three key Atlantis USX messages are:
Why buy more storage when you can do more with the storage you already have
Get up to 5X the capacity out of your existing storage array
Avoid buying any new storage hardware for the next 5 years
Reduce storage costs by up to 75%
Use cases: Storage capacity running out in your current arrays.
Don’t buy another disk tray or array, free up capacity by leveraging Atlantis USX Inline Deduplication.
Get more capacity out of your all-flash array purchase – all-flash arrays (AFA) provide great performance but not great capacity, get 5X more capacity by using USX on-top of your AFA.
Accelerate the performance of your existing storage array
Deliver all-flash performance to applications with your existing storage at a fraction of the cost
Works with any storage system type – SAN, NAS, Hybrid, DAS
Use cases: Current storage arrays not providing enough IOPS to your applications – place USX in front of your array and gain all-flash performance by using RAM from your hypervisor to accelerate and optimize the IO.
Build hyper-converged systems INSTANTLY without buying any new hardware
With RAM, local disk (SSD/SAS/SATA) or VMware VSAN on your existing servers
Don’t replace your servers of choice with alternative appliances
Use blade servers for hyper-converged infrastructure
Use cases: Leverage existing investment in your compute estate by using USX to pool and protect local RAM and DAS to create a hyper-converged solution which can leverage both the DAS and any shared storage resources already deployed, including traditional SAN/NAS and VMware VSAN. Also use your preferred server architecture for hyper-converged, USX allows you to use both blade and rack server form factors due to the reduction in the number of disks required.
What if I want to do all of the above, all at the same time?
You can get the benefits of rich data services coupled with crazy fast storage and in-line deduplication enabling immediate capacity savings today.
What is Inline IO and Data de-duplication?
In short, it is the ability to dedupe data blocks and therefore IO operations before those blocks and IO operations reach the underlying storage. Atlantis USX reduces the load on the underlying storage by processing IO using the distributed in-memory technology within Atlantis USX.
To demonstrate this, the blue graph below represents IOPS provided by USX to VMs. The red graph represents the actual IOPS that USX then sends down to the underlying storage (if it needs to). [The red graph would be for IO operations that are required for unique writes, however I won’t go into detail about that here in this post.]
Conversely, the same graphs can be used to show data de-duplication, just replace the IOPS metric on the y-axis with Capacity Utilization (GB) and you will also see the same savings in the red graph. Atlantis USX uses in-memory in-line de-duplication to offload IOPS from the underlying storage and to reduce consumed capacity on the underlying storage. I’ll show you how this works in the following labs below.
Examples in the lab
Let’s see some of these use cases in action in the lab.
Lab setup
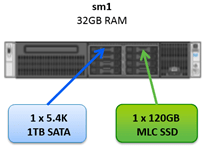
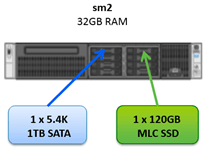
3 x SuperMicro servers installed with vSphere 5.5 U1b with 32GB RAM, 1 x SSD, 1 x SATA and some shared storage (which is not in use in this post) presented from an all-flash array (violin memory) and SAN (Nexenta) both over iSCSI.
Local direct attached storage (DAS) pooled, protected and managed by Atlantis USX.
Use Case 1: Building hyper-converged using Atlantis USX for VDI
In this use case I’ve created a hyper-converged system using the three servers and pooling the local SSDs as a performance pool and the local SATA drives as a capacity pool.
Memory is not used as a performance pool due to the servers only having 32GB of RAM. In a real world deployment you can of course use RAM as the performance pool and not require any SSDs altogether. I’ll use RAM in another blog post.
In the vSphere Client, these disks are shown as local VMFS5 data stores.
Pooling Local Resources
What USX then does is pool the SSDs into a Performance Pool and the SATA disks into a Capacity Pool.
Performance Pools
Atlantis USX pools the SSDs into a Performance Pool to provide performance. Performance Pools provide redundancy and resiliency to the underlying resources. In this example, where we are only using three servers, the RAW capacity provided by the SSDs are 120 x 3 = 360, however due to the Performance Pool providing redundancy, the actual usable capacity will be 66% of this, so 240GB is usable. This is the minimum configuration for a 3-node vSphere cluster. If you had a 4-node cluster then you will have the option to deploy a Performance Pool with a ‘RAID-10’ configuration. This will then give you 480GB RAW and 240GB usable. It’s really up to you to define how local resources are protected by Atlantis USX and by adding more nodes to your vSphere cluster and/or more local resources you can create hyper-converged infrastructure which is truly web scale.
Side note 1: an aside on web scale
Atlantis USX can pool, protect and manage multiple vCenter Servers and their resources. vCenter Servers can manage thousands of vSphere ESXi hosts. You can even create a Virtual Volume from resources which span over multiple ESXi servers, which are not in the same vSphere Cluster and not managed by the same vCenter Server. Heck, you can even use USX to provide the rich data services through Virtual Volumes which use multiple vsanDatastores (VMware VSAN). What I’m trying to say is that your USX Virtual Volume is not restricted to a vCenter construct and as such is free to roam as it is in essence decoupled from any underlying hardware. More on Virtual Volumes later.
Roaming Free
Back to Capacity Pools
Atlantis USX pools the SATA disks into a Capacity Pool to provide capacity. Capacity Pools also provide redundancy and resiliency to the underlying resources. In this example, where we are only using three servers, the RAW capacity provided by the SATA disks are 1000 x 3 = 3000, however due to the Capacity Pool providing redundancy, the actual usable capacity will be 66% of this, so 2000GB is usable.
The resources from the Performance Pool and Capacity Pool are then used to carve out resources to Virtual Volumes.
Side note 2: a quick introduction to Atlantis USX Virtual Volumes
“Virtual Volumes is all about making the storage VM-centric – in other words making the VMDK a first class citizen in the storage world” – Cormac Hogan
Your application should be able to define its own set of requirements and then the storage will configure itself to accommodate the application. Some of these requirements could be:
The amount of capacity
The performance – IOPS and latency
The level of availability – backup and replication
The isolation level – single virtual volume container just for this application or shared between multiple applications of a similar workload
With Atlantis USX, Virtual Volumes have a storage policy which defines those exact requirements. Atlantis USX will provide the rich data services for the virtual volumes which can then be consumed by the application at the request of an Application Owner. Enabling self-service storage request and management for an application without waiting for a storage admin to calculate the RAID level and getting your LUN two weeks later. Is this still happening?
An Atlantis USX Virtual Volume is created from some memory from the hypervisor, some resource from the Performance Pool and some resource from the Capacity Pool. The Atlantis USX rich data services – inline data deduplication and content aware IO processing happens at the Virtual Volume level. The Virtual Volume is then exported by Atlantis USX as NFS or iSCSI (today. Object and CIFS very soon) either to the underlying hypervisor as a datastore or directly to the application. Think of a Virtual Volume as either a) an application container or b) a datastore – all with the storage policy characteristics as explained above and of course supporting all of the lovely vSphere, Horizon View, vCloud, VCAC features that you’ve come to love and depend on:
HA
DRS
vMotion
Fault Tolerance
Snapshots
Thin Provisioning
vSphere Replication
Storage Profiles
Linked Clones
Fast Provisioning
VAAI
Back to creating Virtual Volumes from Pools
In our example here, the maximum size for one Virtual Volume would be constructed from 240GB from the Performance Pool and 2000GB from the Capacity Pool. However, to take advantage of Atlantis USX in-memory I/O optimization and de-duplication, you would create multiple Virtual Volumes, one for a particular workload type. Doing so will make the most out of the Atlantis USX Content Aware IO Processing engine.
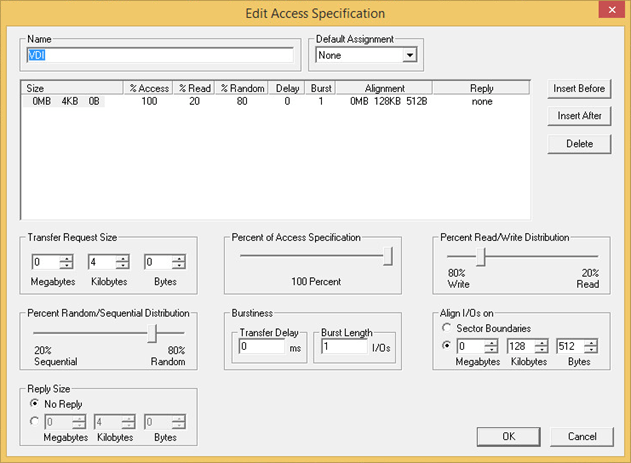
Let’s configure a single Virtual Volume for a VDI use case. I’ll create a Virtual Volume with just 100GB from the Capacity Pool and 5GB from the Performance Pool. We will then deploy some Windows 8 VMs into this Virtual Volume and see the Atlantis USX in-memory data deduplication and content aware IO processing in action.
Here’s our Virtual Volume below, configured from 100GB of resilient SATA and just 5GB of resilient SSD. Note that VAAI integration is supported and for NFS the following primitives are currently available: ‘Full File Clone’ and ‘Fast File Clone/Native Snapshot Support’.
[Dear VMware, how about a new ‘Drive Type’ label named ‘In-Memory’, ‘USX’, ‘Crazy Fast’?]
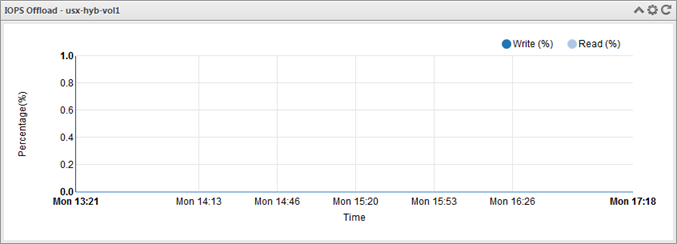
As you can see the datastore is empty. Very empty. The status graphs within USX currently show no IO offload and no deduplication. There’s nothing to dedupe and no IO to process.
Let’s start using this datastore by cloning a Windows 8 template into it. We will immediately see deduplication savings on the full clone after it is copied to our new virtual volume.
Here’s our new template, cloned from the ‘Windows 8.1 Template’ template above which is now located on the new usx-hyb-vol1 virtual volume.
The same graph below shows that for just that single workload, USX has been able to perform data de-duplication by 18%.
Let’s jump into Horizon View and create a desktop pool and use Full Clones for any new desktops, I’ll use the template named win8-template-on-usx as the base template for the new desktop pool and our new virtual volume usx-hyb-vol1 as the datastore.
Let’s see what happens when we deploy one new virtual machine via a full clone with Horizon View which uses an Atlantis USX Virtual Volume. Hint: The clone happens almost instantly due to the VAAI Full Clone offload to USX. We will also see the deduplication ratio increase and IO offload will also increase.
The Full Clone completes in about 9 seconds. Happy days!
The deduplication has increased to 63%! With just two VMs on this datastore – the template win8-template-on-usx and the first VM usx-vdi1.
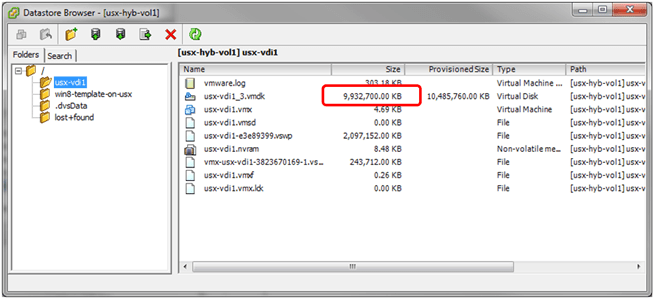
Taking a look with the vSphere Client datastore browser again, we now see two VMs in the virtual volume which are both full VMs, not linked clones.
Two Full VMs, only occupying 8.9GB.
Let’s now go ahead and deploy an additional 5 VMs using Horizon View.
All five new VMs are provisioned pretty much instantly as shown in the vSphere Client Recent Tasks pane.
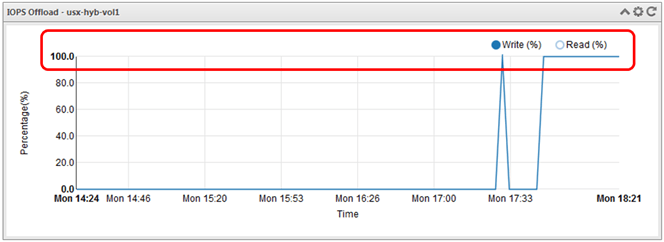
Checking the Atlantis USX status graphs again, the deduplication ratio has increased to 88%.
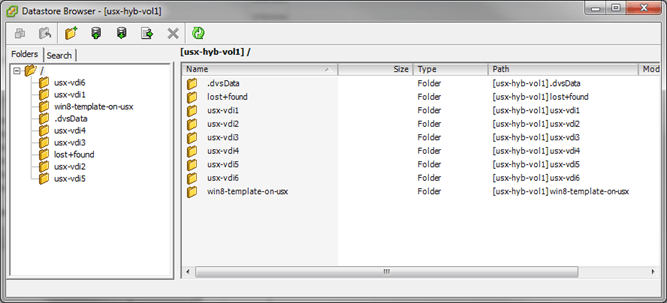
And we now see 6 Full Clones and the template in the datastore but still just consuming 10.57GB.
Additionally because the workloads are pretty much exactly the same, with all six VMs deployed and running in the usx-hyb-vol1 Virtual Volume and with Atlantis USX in-memory Content Aware IO processing, IO and data de-duplication, the IO Offload is pretty much at 100%. This will decrease accordingly as users start using the virtual desktops and more unique data is created but Atlantis USX will always try to provide all IO from the Performance Pool (RAM, Flash or SSD).
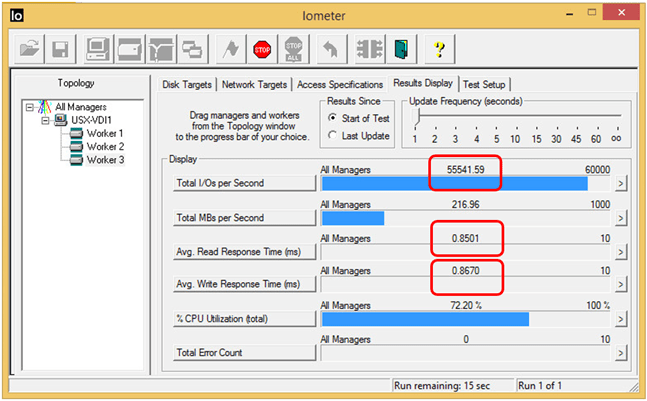
No storage blog post is complete without an Iometer test
55k IOPS (fifty five thousand IOPS!) and pretty much negligible read and write latency on just three vSphere ESXi hosts. To put that into context, if I deployed one hundred Windows 8 VDI desktops into that Virtual Volume, each desktop (and therefore user) would basically have 550 IOPS. You can read more about IOPS per user in this post by Brian Madden (http://searchvirtualstorage.techtarget.com/video/Brian-Madden-discusses-VDI-IOPS-SSD-storageless-VDI). To put this IOPS number into further context, that Virtual Volume is configured to use just 10GB of RAM from the hypervisor, 5GB of SSD and 100GB (of which only 10.57GB is in use, which is a 88% capacity saving) of super slow SATA disks in total over the three vSphere ESXi hosts. If you want more IOPS, you just need to create more Virtual Volumes or add more ESXi hosts to scale out the hyper-converged solution.
In other words… crazy performance on hyper converged architecture with just a few off-the shelf disks on a few servers. No unicorns or magic in Atlantis USX, just pure speed and space savings. BOOM!
Summary
To summarize, Atlantis USX is a software-defined storage solution that delivers the performance of an All-Flash Array at half the cost of traditional SAN or NAS. You can pool any SAN, NAS or DAS storage and accelerate its performance, while at the same time consolidating storage to increase storage capacity by up to five times. With Atlantis USX, you can avoid purchasing additional storage for more than five years, meet the performance needs of any application without buying hardware, and transition from costly shared storage systems to lower cost hyper-converged systems based on direct-attached storage as I’ve demonstrated here.
In part 2. I’ll use local RAM instead of SSDs and in part 3. I’ll demonstrate how Atlantis USX can be used to get more capacity and IOPS from your current storage array.