
Heres a picture of the box…
Author: Hugo Phan
@hugophan
Disaster Recovery just got "sESXi"
Notes on using vRanger Pro & ESXi for Disaster Recovery
Just succesffully proved vRanger Pro to restore backups taken from Production (ESX 3.5, vRanger Pro on physical with VCB) to infrastructure in DR (ESXi 3.5, vRanger Pro on a VM, non VCB). All this from provisioning DR Infrastructure (ESXi Servers, Storage, vCenter VM) within 1 hour. Silver tier recovery just got “sESXi”!
Infrastructure at Production
- ESX 3.5 Update 2 on BL460C
- Storage on 400Gb LUNs presented by IBM SVC
- VC 2.5 Update 2 VM
- vRanger 3.8.2.1 & VCB 1.5 & vRanger Pro VCB Plugin 3.0 on Physical DL380 G5 Server
- VM backups on TSM and replicated to DR
Infrastructure at DR
- ESXi Update 3 USB on DL360 G5
- Local Storage
- VC 2.5 Update 4 VM
- vRanger 3.2.9.7 & VCB 1.5 & vRanger Pro VCB Plugin 3.0 on W2K3 SP2 VM + .Net Framework 2.0 SP1
Important points to note
If you are running vRanger in a virtual machine to restore workloads backed up by vRanger installed on a physical host, with either traditional LAN based backup or VCB based backup. It is important that the software is installed in the correct order and all the necessary software is installed to enable vRanger to restore both types of backup. If the physical vRanger server performed a backup of a workload using the VCB framework, then you will not be able to restore that workload using another vRanger server unless the VCB framework is also installed. For example, you wish to perform a restore at a DR site.
The correct installation order is
- Microsoft .Net Framework 2.0 SP1
- vRanger Pro
- vRanger Pro VCB Integration module
- vRanger Pro file-level plugin
- VMware VCB Framework
Tips
- Install software in the correct order
- Create the same directory structure for the VM at the DR site as it is at Production. E.g, if the vRanger working directory is D:\vRanger_Backups at Production, then keep the same directory structure for the vRanger server at DR.
- This will enable you to first restore the vRanger database (esxRanger.mdb), which then populates the Restore table saving valuable time and effort because you will no longer need to use “Restore from Info”
- If restoring a vRanger backup that was taken using the VCB framework, then the vRanger server at DR will also need to have the VCB framework installed.
What to do when an ESX host shows not responding?
Steps in order to progress
1) Login in the affected ESX server using Putty
2) service mgmt-vmware restart
If this doesn’t work then the vmware-hostd daemon has to be killed.
3) ps -e | grep vmware-hostd
Look for the process_id associated with vmware-hostd
4) kill process_id
i.e. if 3) returned:
32470 ? 00:01:12 vmware-hostd
the command would be:
kill 32470
5) service mgmt-vmware status
if the service is started use
service mgmt-vmware restart
if it’s stopped use:
service mgmt-vmware start
Using ESX 3.5 vmware-vim-cmd instead of vimsh
vmware-vim-cmd
For those of you familiar with vimsh and used it to configure a scripted install of ESX 3.5, have you noticed that the following error would occur when launching commands using /usr/bin/vimsh ?
/usr/bin/vimsh -n -e “hostsvc/maintenance_mode_enter

Alternatively, by using the wrapper developed for ESX 3.5, vmware-vim-cmd, you would get the following:
/usr/bin/vmware-vim-cmd hostsvc/maintenance_mode_enter

The two commands are detailed in the Xtravirt whitepapers, vimsh and vimsh for ESX 3.5. I would recommend at least having a quick browse to see what can be achieved with these commands. Using vmware-vim-cmd in conjunction with esxcfg- can achieve some very interesting results, especially if you love to create the perfect KickStart build script.
If only it is possible to launch vmware-vim-cmd commands using the RCLI just as esxcfg- can be launched using vicfg-. Anyone have an idea?
A few more examples
Refreshing the network settings
/usr/bin/vmware-vim-cmd hostsvc/net/refresh
Refreshing the storage
/usr/bin/vmware-vim-cmd hostsvc/storage/refresh
The all important enabling VMotion
/usr/bin/vmware-vim-cmd hostsvc/vmotion/vnic_set vmk0
And how about setting vSwitch1 to use Route Based on IP Hash?
/usr/bin/vmware-vim-cmd hostsvc/net/vswitch_setpolicy –nicteaming-policy=loadbalance_ip vSwitch1
And setting vSwitch0 to use Route Based on the Originating Virtual PortID. (vSwitch0 has two portgroups using VLAN tagging, 1 for Service Console and 1 for VMotion, we wish to use active-passive nic teaming policy)
Set active vmnic0 and standby vmnic2 for Service Console
/usr/bin/vmware-vim-cmd hostsvc/net/portgroup_set –nicorderpolicy-active=vmnic0 vSwitch0 ‘Service Console’
/usr/bin/vmware-vim-cmd hostsvc/net/portgroup_set –nicorderpolicy-standby=vmnic2 vSwitch0 ‘Service Console’
Set active vmnic2 and standby vmnic0 for VMkernel network
/usr/bin/vmware-vim-cmd hostsvc/net/portgroup_set –nicorderpolicy-active=vmnic2 vSwitch0 VMkernel
/usr/bin/vmware-vim-cmd hostsvc/net/portgroup_set –nicorderpolicy-standby=vmnic0 vSwitch0 VMkernel
Set vSwitch overide load balancing policy
/usr/bin/vmware-vim-cmd hostsvc/net/portgroup_set –nicteaming-policy=loadbalance_srcid vSwitch0 ‘Service Console’
/usr/bin/vmware-vim-cmd hostsvc/net/portgroup_set –nicteaming-policy=loadbalance_srcid vSwitch0 VMkernel
Let’s not forget to refresh our network settings
/usr/bin/vmware-vim-cmd hostsvc/net/refresh
/usr/bin/vmware-vim-cmd internalsvc/refresh_network
A Comparison of HyperVisors
You can download the zip file from here.
Video: Install Hyper-V and ESXi

The article can be read at source here
Changing the HBA queue depths on multiple dual-port adapters
Following on from optimising the storage for a customer, I decided to change the queue depths for the Emulex HBAs. The ESX hosts, each have two dual-port Emulex HBAs, the diagram below shows the setup..

Only two ports are in use at the moment, vmhba2 and vmhba5. To determine the instance numbers that are in use by the Emulex ESX driver – lpfc (use qla2300 or similar for QLogic), the output of the ls command includes a number for each active HBA in the system. We can then use the instance numbers to find the active adapters.
Emulex example
# ls /proc/scsi/lpfc
You should get an output similar to

Because of the way that the host is connected and from the picture above, I already know that 2 and 5 are the active adapters. Running the following command will confirm
# cat /proc/scsi/lpfc/2
 this shows that vmhba2 is currently active and has 4-paths to the SAN
this shows that vmhba2 is currently active and has 4-paths to the SAN
Running the same command on vmhba3 gives the following as expected
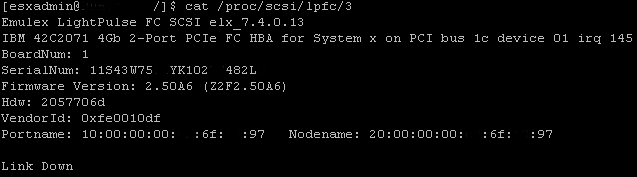
Running the command on vmhba5 is also as expected.
Now that we’ve found out which vmhbas are active, we can use the output to find out which lpfc# options we should add to the lpfc_740.o module to configure the queue length.
The outputs of # cat /proc/scsi/lpfc/2 and # cat /proc/scsi/lpfc/5, give us lpfc numbers of 0 and 3 respectively. So to configure a queue depth of 64 for lpfc2 and lpfc5 we run the following command
# esxcfg-module -s “lpfc0_lun_queue_depth=64 lpfc3_lun_queue_depth=64” lpfc_740
and
# esxcfg-boot -b
 The -q option shows configured options for a module.
The -q option shows configured options for a module.
Now we reboot for the changes to take effect.
In this case, both HBAs lpfc0 (vmhba2) and lpfc3 (vmhba5) will have their queue depths set to 64.
With this post and the previous one, we have set manual load balancing for the LUNs over eight different paths and also changed the queue depth to 64, this should keep the ESX optimised for now, maybe I’ll change the VMFS3.MaxHeapSizeMB to 64 for good measure!
Using RCLI to configure multiple ESX 3.5 Servers
So I deal with a lot of customers on my travels, and most have multiple ESX servers and occasionally I receive the odd request for a change here and there. As you all know, with VI3 and the latest releases of ESX3.5/VC2.5, almost all configuration and most advanced configuration can be achieved by using the VI Client connected to VirtualCenter.
But how long would it take to add another portgroup to a vSwitch with a VLAN ID for 20 ESX servers? Quite long, if you have the time or the patience then thats fine, but I’d rather script something like that.
By using the VMware RCLI (Remote Client) you can send vicfg- (esxcfg) commands to both ESX 3.5 and ESXi hosts. Originally it was intended for use with ESXi due to it having limited service console but the functionality is also provided for ESX 3.5 hosts.
The VMware Infrastructure Remote CLI provides a command-line interface for datacenter management from a remote server. This interface is fully supported on VMware ESXi 3.5 and experimental for VMware ESX 3.5. Storage VMotion is a feature that lets you migrate a virtual machine from one datastore to another. It is used by executing the svmotion command from the Remote CLI. The svmotion command, unlike other RCLI commands, is fully supported for VMware ESX 3.5.
I use the RCLI with SSH access enabled, so now my RCLI acts as a service console proxy server. To send an esxcfg- command to an ESX 3.5 host, I would now log into the RCLI using SSH and then send the commands from the RCLI’s command line, or execute a .sh script on the RCLI.
So let’s use our example above…. to add another portgroup to vSwitch1, with a VLAN ID of 123 onto 20 ESX 3.5 hosts.
- Log into the RCLI using SSH
- the command line command is very similar to esxcfg- but we use vicfg- instead
- vicfg-vswitch –add-pg=VLAN123 vSwitch1 –server= –username=root –password=
- Now you can either repeat the above for all 20 servers or script it into a shell script..
- Create a new script on the RCLI called addportgroup.sh
#!/bin/sh
#Script to add portgroup with vlad id of 123 to vSwitch1 onto all ESX 3.5 hosts
# Assign port groups to vSwitch1
vicfg-vswitch –add-pg=VLAN123 vSwitch1 –server= –username=root –password=
vicfg-vswitch –add-pg=VLAN123 vSwitch1 –server= –username=root –password=
vicfg-vswitch –add-pg=VLAN123 vSwitch1 –server= –username=root –password=
#Assign vlan ids to port groups
vicfg-vswitch -v 123 -p VLAN123 vSwitch1 –server= –username=root –password=
vicfg-vswitch -v 123 -p VLAN123 vSwitch1 –server= –username=root –password=
vicfg-vswitch -v 123 -p VLAN123 vSwitch1 –server= –username=root –password=
Now save, make the script executable and then launch it, and the script will create the new portgroups on all the servers in a couple of seconds.
Until Round Robin is here.. how to Load Balance over Active/Active Paths using scripts
Recently a customer had a few issues with having all VMs using the same path to the LUNs, this was down to putting too many workloads onto servers that were used as a proof of concept. Inadvertently, SAN problems arose so I was asked to checkover the storage.
First a little background on the infrastructure…. a number of rack servers plus a number of blade servers, hooked into two fabrics with IBM SVC as the backend. Each ESX server has two FC HBA, and each fabric switch had two connections to the SVC, therefore each ESX server has four possible paths to the LUNs. The paths were all active as shown on this pic:
 As you can see the path policy is currently set to mru, most recently used path policy is best used in an active/passive configuration.
As you can see the path policy is currently set to mru, most recently used path policy is best used in an active/passive configuration.
mru:
- LUNs presented on single Storage Processor at any one time
- Failover on NOT_READY, ILLEGAL_REQUEST or NO_CONNECT
- No preferred path policy
- No failback to preferred path if it returns online after failover
Since, esxcfg-mpath -l shows that we are in fact using active/active, it is best to change the policy to fixed path policy:
- LUNs presented on multiple Storage Processors at same time
- Failover over on NO_CONNECT
- Preferred path policy
- Failback to preferred path if it returns online after failover
So how do we now go about changing the policies on all our servers? Well we could use VI-Client and change each datastore to use a different path – doing this for 10 datastores per server with 20+ servers? howabout no! The alternative then would be to script it.
The script from Yellow Bricks is of particular use, as for each LUN it finds it uses a different path for each LUN. The script just sets each LUN up to use a preferred path, but obviously for default installations of ESX, you cannot use preferred path when you are using mru policy. So we must change all LUNs to use fixed path policy first.
By re-using the script form Yellow Bricks, I’ve come up with this:
#!/bin/bash
# vmhbafixedpath.sh Script to rescan vmhbas on ESX 3.5 host
# Written by hugo@vmwire.com
# 21/05/2008 18:20
for PATHS in 2 4 6 8
do
STPATHS=${PATHS}
COUNTER=”1″
for LUN in $(esxcfg-mpath -l | grep “has ${STPATHS} paths” | awk ‘{print $2}’)
do
esxcfg-mpath –lun=${LUN} -p fixed
COUNT=`expr ${COUNTER} + 1`
COUNTER=${COUNT}
if [[ ${COUNTER} -gt ${STPATHS} ]]
then
COUNTER=”1″
fi
done
done
Then use the script from Yellow Bricks, to set up the preferred paths. Now the changes do not take into effect until the HBAs are rescanned, and the Storage is refreshed. The following script rescans the HBAs
#!/bin/bash
# rescanhbas.sh Script to rescan vmhbas on ESX 3.5 host
# Written by hugo@vmwire.com & nkouts
# 21/05/2008 18:50
# Assumes there is no vmhba0 and max vmhba9
for HBAS in 2 4
do
STHBAS=${HBAS}
COUNTER=”1″
for HBA in $(esxcfg-info -w | grep vmhba | awk ‘{print $3}’ | grep -e ‘vmhba\+[1-9]’ -o)
do
esxcfg-rescan ${HBA}
COUNT=`expr ${COUNTER} + 1`
COUNTER=${COUNT}
if [[ ${COUNTER} -gt ${STHBAS} ]]
then
COUNTER=”1″
fi
done
done
And there is no known console based method to refresh the storage subsystem (anyone?) apart from using VI-Client, rebooting the ESX host or restarting the vmware management service:

service mgmt-vmware restart

UPDATE: Use /usr/bin/vmware-vim-cmd to refresh the storage
/usr/bin/vmware-vim-cmd hostsvc/storage/refresh
So now we have the servers using different paths for each datastore.

It only took a couple of seconds to change the policies on each server using these scripts, obviously using these as part of a build script would be ideal for deployments where you know the SAN configuration.
VCDX: An overview
VCDX: VMware Certified Design Expert
VCDX is not a follow on from VCP and is not currently a VAC or Partner program requirement, this should be seen as an advanced Certification and is only applicable to architects who have designed and deployed enterprise environments. The Enterprise Exam is available this month. Candidates can check their skills and assess their suitability for this exam online via our Certification page : http://mylearn1.vmware.com/portals/certification/ Only those who meet these qualifications will be able to attend the exams. The Design exam is now in Beta development. We expect design submissions and presentations will begin in Q308.
The BluePrint is available now, use as a tick list… all 16 pages of it. 🙂
Here’s a summary of what I know about the VCDX over the last few days….
To attain the VCDX, one needs to achieve…
1. VCP
2. Pass the Enterprise Exam
3. Pass the Design Exam
4. Successfully pass a grilling by your peers, most likely chaps from VMware PSO on a design and implementation plan.
Now, according to my sources, the official preparation, and non-compulsory, for the Enterprise Exam is the DSA Course:
VI3: DSA v3.5
Duration 4 days
RRP £2095 p/p
It’s upto you to decide if you really need to go on the course to pass, so a read of the blueprint will probably give you a guide as to the level that you are at.
The official preparation for the Design Exam, also non compulsory are two new, unreleased courses from VMware, the first is aptly named Design Patterns (release Q3/Q4) and the second course is an unknown at the moment.
Update: ESX 3.5 on HS21 XM (7995)
IBM came back with a workaround to my problem,….All workarounds have been tested and work.
The workarounds then for anyone running ESX 3.5 Build 64607 on HS21 XM 7995 v1.08 with 2 x quad core CPUs:
1. Use ESXi instead (No service console, hence no PSOD. Also no mouse services in the console needed, hence no PSOD (this is the problem that I was experiencing).
2. Use ESX 3.5 Up 1 Build 82663 (Stable as of 18th April – double check your checksums!)
3. Use ESX 3.5 build 64607 but disable the gpm module, do this by entering the following on the Service Console:
chkconfig gpm off
then reboot the host, obviously you will get a PSOD but reset it and all should be well thereafter.
Er… problem with HS21 XM (7995) and ESX 3.5
This is a bit of an issue. I’ve just test installed ESX 3.5 onto a HS21 XM (7995) blade BIOS v 1.07, everything is fine and the server boots fine and runs stable but everytime I reboot from the console or restart using VI-Client I get a purple screen of death.
Now I know that there is an issue with quad-core Xeons and HS21 blades, but wasn’t this fixed with the latest BIOS versions? I believe it was fixed with BIOS 1.06 on the normal HS21 but was this same fix applied to HS21 XM (7995) v 1.07?
IBM and VMware support tickets have been opened, but any working fixes out there?
Does anyone know what this tool is?
It was used in “Fundamentals of Disaster Recovery in Virtualized Environments” VMware World Partner Day 2007.
 Any help to indentify would be great!
Any help to indentify would be great!
Planning a VMware ESX deployment on IBM BladeCenter H – Part 2
In the previous post I covered the network design for a HS21 with 4 network interfaces. This post will continue with a diagrammatic representation of the interface table.
As described previously, this configuration provides full network fault tolerance on all levels: adapter, port, CAT5, switch bay and core switch.
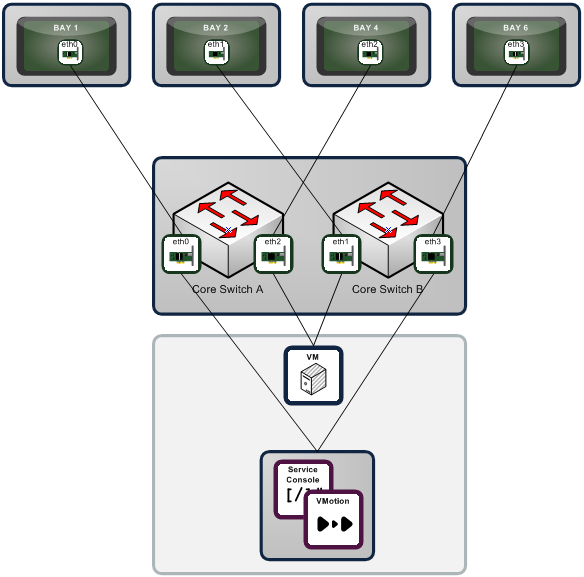 Put your finger over any individual constituent part, i.e., pNic, interface, bay switch or core switch, to simulate a failure and there will always be an alternative path.
Put your finger over any individual constituent part, i.e., pNic, interface, bay switch or core switch, to simulate a failure and there will always be an alternative path.
I’m waiting for the customer to decide on whether to include the CFFv daughtercard in this phase of the project, and will update this post with the new design if required.
Next up, environmentals…
Those of you familiar with the HP c-Class blades will probably know that there is a superb tool called the HP BladeSystem PowerSizer 2.9, I’ve been trying to find an equivalent from IBM, but as yet have not found anything that comes as close. (Any pointers will be appreciated)
Instead I’ve had to resort to using data obtained from The Edison Group study titled Blade Server Power Study – IBM BladeCenter and HP BladeSystem, Nov 7 2007, document titled “BLL03002USEN.pdf“.
The results show, in summary a BladeCenter H chassis with 14 blades on full load will need 14,352.51 BTU/Hr with a peak power consumption of 4,208.80 Watts. Most modern datacenters with good power feeds will be able to accommodate that kind of load. Cooling requirements will be left to the customer to calculate.
Additionally, this single chassis will require 9 rack units and 4 power feeds due to the additional 2900W power supply modules.
Part 2…. Continued..
Thank you Aaron for your help with the power sizer.
Here is the output from the tool (not as nice as HP’s offerring by the way)

In the next part… network design for the x3650.
Planning a VMware ESX deployment on IBM BladeCenter H – Part 1
Well here I am, starting a new project for a new customer at a new datacenter again. This time, its a large retail organisation looking to do the usual, consolidate, virtualise, go green etc etc. They have selected IBM System X and BladeCenter H as the platforms of choice for the new VMware ESX 3 environment. So here we go with the planning….
The BladeCenter H has eight switch bays and two Advanced Management Module (AMM) bays. The two AMM act in much the same way as the Onboard Administrator on HP C Class. There are two for redundancy. Two of the eight switch bays are used for FC Switches, for this project we are using Brocade 4Gb SAN switches.
The other bays are occupied by Cisco GbE Switch Modules.
HS21s are used for the initial phase of the project. These blades can accommodate upto 6 NICs and 2 HBAs, with 2 onboard and the other 4 provided by daughtercards. The customer has elected to use 4 NICs as opposed to the 6 that I normally recommend for ESX implementations. The two extra NICs are provided by the CFFh daughtercard, this daughtercard houses 2 network adapters AND 2 Fibre Channel HBAs.
The table below (from IBM) show the interface to bay mapping.
 Since only 4 interfaces are available, teaming and VLANs will have to be used to provide resilience and to separate the SC and VMKernel networks.
Since only 4 interfaces are available, teaming and VLANs will have to be used to provide resilience and to separate the SC and VMKernel networks.
I will be teaming Interface 0 (eth0) with Interface 3 (eth3) as opposed to the IBM table (dedicating an adapter to a service), as this will team one onboard port with one daughtercard port. Likewise eth1 will then be teamed with eth2.
* The location of the two Fibre Channel Adapters should be Daughter Card CFF-h, not v as shown in the IBM table.
The following diagram shows the correct mapping.

The table below details the network interconnects.
 Interface is the network adapter inside a blade, Location is where the interface is, Chassis Bay is where the interface terminates at the rear of the BladeCenter chassis, pSwitch is the external core switch that the Chassis Bay uplinks to, vSwitch is the ESX virtual switch that the Interface provides an uplink for, vLAN is the ID that is assigned to each Port Group and Service is the type of port group assigned to a vSwitch.
Interface is the network adapter inside a blade, Location is where the interface is, Chassis Bay is where the interface terminates at the rear of the BladeCenter chassis, pSwitch is the external core switch that the Chassis Bay uplinks to, vSwitch is the ESX virtual switch that the Interface provides an uplink for, vLAN is the ID that is assigned to each Port Group and Service is the type of port group assigned to a vSwitch.
How to disable host only networking dhcp server on Linux hosts
Disabling the VMware DHCP Service on the Host Computer.
It is easy enough to do this on Windows hosts, this article focuses on Linux hosts.
Follow the steps shown below for your host operating system.
Linux for Workstation 5.x and VMware Server 1.x
- Open the file /usr/lib/vmware/net-services.sh in a text editor.
- Locate the following section (lines 697-699, as seen in Workstation 5.5.1, build 19175):
vmware_bg_exec ‘Host-only networking on /dev/vmnet'”$vHubNr” \
vmware_start_hostonly “$vHubNr” ‘vmnet'”$vHubNr” \
“$hostaddr” “$netmask” ‘yes’ - Change yes to no. The resulting section should look like this:
vmware_bg_exec ‘Host-only networking on /dev/vmnet'”$vHubNr” \
vmware_start_hostonly “$vHubNr” ‘vmnet'”$vHubNr” \
“$hostaddr” “$netmask” ‘no’ - Save the file.
- As root, run /usr/lib/vmware/net-services.sh restart to restart the service.
Linux for Workstation 6
- As root, stop VMware services using /etc/init.d/vmware stop
- Open the file /etc/vmware/locations in a text editor.
- Scroll all the way to the bottom.
- Look for answer VNET_1_DHCP yes, change this to answer VNET_1_DHCP no
- Continue for any other interfaces that you would like to disable DHCP.
- Save the file.
- As root, start VMware services using /etc/init.d/vmware start
Checking the state of a running VM and killing the process if required
Occasionally you may want to check the state of a virtual machine, to check whether it is running or not. On the very few times that VMotion failed for one reason or another, a VM will fail to resume on the source host or start on the destination host.
From the Service Console you can check the state of running machines by typing vmware-cmd //server.vmx getstate. You can also kill the VM if it is truly in a hung state by using the procedure below.
- Login to the service console
- You can check the VM state by typing vmware-cmd //server.vmx getstate
- Type ps -ef | grep
- The second column is your pid of the vmkload_app of the Virtual Machine, you can also type ps –eaf to see all running processes
- Type kill -9
- Check VM state again, it should now be off
- Type vmware-cmd //server.vmx start to power on VM
Show hidden devices after P2V
After performing a P2V always remove the hidden physical hardware from the OS. This is particularly important for network cards that have the original IP address(es) that you want to assisgn to the new VM.
1. Click Start | Run | cmd
2. At a command prompt, type the following command , and then press ENTER:
set devmgr_show_nonpresent_devices=1
3. Type the following command in the same command prompt window, and then press ENTER:
start devmgmt.msc
4. Click Show hidden devices on the View menu in Device Managers before you can see devices that are not connected to the computer.
Syncing ESX Server with an external time source
To sync your ESX Server with an external NTP server, do the following at the ESX Server console… Basically you can do the following (replace with the IP Address of an NTP Server.)
Modify the /etc/ntp.conf file as follows:
Under the “# — OUR TIMESERVERS —–“ section create two lines as follows:
restrict mask 255.255.255.255 nomodify notrap noquery
server
Modify the /etc/ntp/step-tickers file and add your NTP Servers, each on their own line, to the file.
Enable the appropriate NTP client ports on the firewall.
/usr/sbin/esxcfg-firewall –enableService ntpClient
Restart the vmware-hostd process.
/sbin/service mgmt-vmware restart
To synchronize the system’s time with the NTP server
/usr/sbin/ntpdate -q
To enable the ntp daemon to autostart when the server is rebooted
/sbin/chkconfig –level 345 ntpd on
Start NTP daemon
/sbin/service ntpd start
Set the local hardware clock to the NTP synchronized local system time
/sbin/hwclock –systohc
Ensure the time is accurate
/bin/date
